BERT de Google: Comment BERT a lancé une fusée dans la compréhension du langage naturel
Obtenez l'historique complet de l'évolution de l'algorithme et de la façon dont BERT a amélioré la compréhension du langage humain pour les machines.

Dans cet article, vous allez tout savoir sur le fonctionnement de l'algorithme BERTde Google et comment les moteurs de recherche l'utilisent? Vous pouvez même apprendre comment les référenceurs l'utilisent.
Note de l'éditeur Dawn Anderson de searchengineland: ce compagnon de plongée en profondeur de notre FAQ de haut niveau est une lecture de 30 minutes, alors installez-vous confortablement! Vous apprendrez la trame de fond et les nuances de l'évolution de BERT, comment l'algorithme fonctionne pour améliorer la compréhension du langage humain pour les machines et ce que cela signifie pour le référencement et le travail que nous faisons tous les jours.
Si vous avez gardé un œil sur le référencement Twitter au cours de la semaine dernière, vous aurez probablement remarqué une légère augmentation du nombre de gifs et d'images représentant le personnage Bert (et parfois Ernie) de Sesame Street.
En effet, la semaine dernière, Google a annoncé qu'une mise à jour algorithmique imminente allait être déployée, affectant 10% des requêtes dans les résultats de recherche, et affectant également les résultats d'extraits en vedette dans les pays où ils étaient présents; ce qui n'est pas anodin.
La mise à jour s'appelle Google BERT (d'où la connexion Sesame Street - et les gifs).
Google décrit le BERT comme le plus grand changement à son système de recherche depuis que la société a introduit RankBrain , il y a près de cinq ans, et probablement l'un des plus grands changements dans la recherche jamais.
La nouvelle de l'arrivée du BERT et de son impact imminent a provoqué une agitation dans la communauté SEO, ainsi qu'une certaine confusion quant à ce que fait le BERT et ce qu'il signifie pour l'industrie dans son ensemble.
Dans cet esprit, jetons un coup d'œil à ce qu'est le BERT, à ses antécédents, à la nécessité du BERT et aux défis qu'il vise à résoudre, à la situation actuelle (c'est-à-dire ce que cela signifie pour le référencement) et où les choses pourraient se diriger.
Qu'est-ce que le BERT?
Le BERT est un modèle / cadre de traitement du langage naturel révolutionnaire qui a pris d'assaut le monde de l'apprentissage automatique depuis sa sortie en tant que document de recherche universitaire. Le document de recherche est intitulé BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin et al, 2018).
À la suite de la publication d'un article, l'équipe de Google AI Research a annoncé que le BERT serait une contribution open source .
Un an plus tard, Google a annoncé le lancement d'une mise à jour algorithmique Google BERT dans la recherche de production. Google a lié la mise à jour algorithmique du BERT au document de recherche du BERT, soulignant l'importance du BERT pour la compréhension du langage contextuel dans le contenu et les requêtes, et donc l'intention, en particulier pour la recherche conversationnelle.
Alors, qu'est-ce que le BERT?
Le BERT est décrit comme un cadre de langage naturel d'apprentissage en profondeur pré-formé qui a donné des résultats de pointe sur une grande variété de tâches de traitement du langage naturel. Au stade de la recherche et avant d'être ajouté aux systèmes de recherche de production, le BERT a obtenu des résultats de pointe sur 11 tâches de traitement du langage naturel différentes. Ces tâches de traitement du langage naturel comprennent, entre autres, l'analyse des sentiments, la détermination d'entités nommées, l'implication textuelle (alias prédiction de la phrase suivante), l'étiquetage des rôles sémantiques, la classification des textes et la résolution des coréférences. Le BERT aide également à la désambiguïsation de mots avec des significations multiples appelées mots polysémiques, dans leur contexte.
BERT est considéré comme un modèle dans de nombreux articles, cependant, il s'agit davantage d'un cadre, car il fournit la base pour les praticiens de l'apprentissage automatique pour construire leurs propres versions de type BERT affinées pour répondre à une multitude de tâches différentes, et cela est probablement la façon dont Google l'implémente également.
Le BERT était à l'origine pré-formé sur l'ensemble de Wikipedia anglais et de Brown Corpus et est affiné sur les tâches de traitement du langage naturel en aval comme les paires de questions et de réponses. Ainsi, ce n'est pas tant un changement algorithmique ponctuel, mais plutôt une couche fondamentale qui cherche à aider à comprendre et à désambiguïser les nuances linguistiques dans les phrases et les phrases, à se peaufiner continuellement et à s'adapter pour s'améliorer.
Voir aussi: Qu'est-ce que Google MUM et comment cela affectera votre SEO ?
La trame de fond du BERT
Pour commencer à réaliser la valeur apportée par BERT, nous devons examiner les développements antérieurs.
Le défi du langage naturel
Comprendre comment les mots s'articulent avec la structure et le sens est un domaine d'étude lié à la linguistique. La compréhension du langage naturel (NLU), ou NLP, comme on l'appelle par ailleurs, remonte à plus de 60 ans, à l' article de test de Turing original et aux définitions de ce qui constitue l'IA, et peut-être plus tôt.
Ce domaine incontournable est confronté à des problèmes non résolus, dont beaucoup concernent la nature ambiguë du langage (ambiguïté lexicale). Presque tous les autres mots de la langue anglaise ont plusieurs sens.
Ces défis s'étendent naturellement à un réseau de contenu sans cesse croissant alors que les moteurs de recherche tentent d'interpréter l'intention de répondre aux besoins d'information exprimés par les utilisateurs dans des requêtes écrites et orales.
Ambiguïté lexicale
En linguistique, l'ambiguïté se situe au niveau de la phrase plutôt qu'au niveau du mot. Les mots ayant plusieurs sens se combinent pour rendre les phrases et les phrases ambiguës de plus en plus difficiles à comprendre.
Selon Stephen Clark , anciennement de l'Université de Cambridge, et maintenant chercheur à temps plein chez Deepmind:
"L'ambiguïté est le plus grand goulot d'étranglement à l'acquisition de connaissances informatiques, le problème tueur de tout traitement du langage naturel."
Dans l'exemple ci-dessous, tiré de WordNet (une base de données lexicale qui regroupe les mots anglais en synsets (ensembles de synonymes)), nous voyons que le mot «basse» a plusieurs significations, plusieurs se rapportant à la musique et au ton, et certaines relatives au poisson.
De plus, le mot «basse» dans un contexte musical peut être à la fois une partie de discours substantielle ou une partie de discours adjectif, ce qui prête à confusion.
Nom
- S: (n) basse (la partie la plus basse de la gamme musicale)
- S: (n) basse , partie basse (la partie la plus basse de la musique polyphonique)
- S: (n) basse , basso (un chanteur adulte avec la voix la plus basse)
- S: (n) loup de mer, bar (la chair maigre d'un poisson d'eau salée de la famille des Serranidae)
- S: (n) bar d'eau douce, bar (l'un des divers poissons d'eau douce d'Amérique du Nord à chair maigre (en particulier du genre Micropterus))
- S: (n) basse , voix de basse, basso (la voix de chant masculine adulte la plus basse)
- S: (n) basse (le membre avec la gamme la plus basse d'une famille d'instruments de musique)
- S: (n) bar (nom non technique de l'un des nombreux poissons marins à nageoires épineuses et d'eau douce comestibles)
Adjectif
- S: (adj) basse , grave (ayant ou dénotant une gamme vocale ou instrumentale basse) «une voix grave»; «Une voix de basse est plus basse qu'une voix de baryton»; “Une clarinette basse”
Polysémie et homonymie
Les mots ayant plusieurs sens sont considérés comme polysémiques ou homonymes.
Polysémie
Les mots polysémiques sont des mots ayant deux ou plusieurs significations, ayant des racines dans la même origine, et sont extrêmement subtils et nuancés. Le verbe «obtenir», un mot polysémique, par exemple, pourrait signifier «se procurer», «acquérir» ou «comprendre». Un autre verbe, «run» est polysémique et est la plus grande entrée dans le Oxford English Dictionary avec 606 significations différentes .
Homonymie
Les homonymes sont l'autre type principal de mot avec des sens multiples, mais les homonymes sont moins nuancés que les mots polysémiques car leurs significations sont souvent très différentes. Par exemple, «rose», qui est un homonyme, pourrait signifier «se lever» ou ce pourrait être une fleur. Ces significations à deux mots ne sont pas du tout liées.
Homographes et homophones
Les types d'homonymes peuvent également être encore plus précis. 'Rose' et 'Bass' (de l'exemple précédent), sont considérés comme des homographes car ils sont orthographiés de la même manière et ont des significations différentes, tandis que les homophones sont orthographiés différemment, mais sonnent de la même manière. La langue anglaise est particulièrement problématique pour les homophones. Vous pouvez trouver une liste de plus de 400 exemples d'homophones anglais ici , mais quelques exemples d'homophones incluent:
- Brouillon, brouillon
- Double, duel
- Fait, femme de chambre
- Pour, avant, quatre
- Pour, aussi, deux
- Là leur
- Où, porter, étaient
Au niveau d'une phrase, un mot prononcé lorsqu'il est combiné peut soudainement devenir des phrases ambiguës même lorsque les mots eux-mêmes ne sont pas homophones.
Par exemple, les phrases «quatre bougies» et «poignées de fourchette» lors de la division en mots séparés n'ont aucune qualité déroutante et ne sont pas homophones, mais lorsqu'elles sont combinées, elles sonnent presque identiques.
Soudain, ces mots prononcés pouvaient être confondus comme ayant la même signification les uns que les autres tout en ayant des significations entièrement différentes. Même les humains peuvent confondre le sens de phrases comme celles-ci, car les humains ne sont pas parfaits après tout. Par conséquent, les nombreux spectacles de comédie présentent des «jeux de mots» et des nuances linguistiques. Ces nuances parlées peuvent être particulièrement problématiques pour la recherche conversationnelle.
La synonymie est différente
Pour clarifier, les synonymes sont différents de la polysémie et de l'homonymie, car les mots synonymes ont la même signification (ou très similaires), mais sont différents.
Un exemple de mots synonymes serait les adjectifs «minuscule», «petit» et «mini» comme synonymes de «petit».
Résolution de coréférence
Les pronoms comme «ils», «il», «il», «eux», «elle» peuvent aussi être un défi gênant dans la compréhension du langage naturel, et plus encore, les pronoms à la troisième personne, car il est facile de perdre la trace de qui est mentionné dans les phrases et les paragraphes. Le défi du langage présenté par les pronoms est appelé résolution de coréférence , avec des nuances particulières de résolution de coréférence étant une résolution anaphorique ou cataphorique.
Vous pouvez considérer cela simplement comme «être en mesure de garder une trace» de ce qui, ou de qui, est parlé ou écrit, mais ici le défi est expliqué plus en détail.
Résolution des anaphores et des cataphores
La résolution des anaphores est le problème d'essayer de lier les mentions d'éléments comme des pronoms ou des phrases nominales de plus tôt dans un morceau de texte (comme des personnes, des lieux, des choses). La résolution de la cataphora, qui est moins courante que la résolution de l'anaphora, est le défi de comprendre ce qui est appelé un pronom ou une expression nominale avant que la «chose» (personne, lieu, chose) soit mentionnée plus tard dans une phrase ou une phrase.
Voici un exemple de résolution anaphorique:
«John a aidé Mary. Il était gentil."
Où «il» est le pronom (anaphore) pour revenir à «Jean».
Et un autre:
La voiture s'effondre, mais elle fonctionne toujours.
Voici un exemple de cataphora, qui contient également des anaphores:
"Elle était à NYU quand Mary a réalisé qu'elle avait perdu ses clés."
La première «elle» dans l'exemple ci-dessus est la cataphora car elle concerne Marie qui n'a pas encore été mentionnée dans la phrase. La seconde «elle» est une anaphore, car «elle» concerne également Marie, qui a été mentionnée précédemment dans la phrase.
Résolution multi-sententielle
Comme les phrases et les phrases combinent la référence aux personnes, aux lieux et aux choses (entités) comme pronoms, ces références deviennent de plus en plus compliquées à séparer. Cela est particulièrement vrai si plusieurs entités décident de commencer à être ajoutées au texte, ainsi que le nombre croissant de phrases.
Voici un exemple de cette explication de Cornell de la résolution de la coréférence et de l'anaphore:
a) John a fait deux voyages à travers la France.
b) Ils étaient tous les deux merveilleux.
Humains et ambiguïté
Bien qu'imparfaits, les humains ne sont généralement pas concernés par ces défis lexicaux de résolution de coréférence et de polysémie, car nous avons une notion de compréhension de bon sens.
Nous comprenons à quoi «elle» ou «ils» se réfèrent lorsque vous lisez plusieurs phrases et paragraphes ou entendez des conversations de va-et-vient, car nous pouvons garder une trace de qui est le sujet d'attention.
Nous réalisons automatiquement, par exemple, lorsqu'une phrase contient d'autres mots apparentés, comme «dépôt» ou «chèque / chèque» et «espèces», car tout cela concerne la «banque» en tant qu'institut financier, plutôt qu'une «rivière» . "
En termes de mots, nous sommes conscients du contexte dans lequel les mots et les phrases sont prononcés ou écrits; et cela a du sens pour nous. Nous sommes donc en mesure de gérer relativement facilement l'ambiguïté et les nuances.
Machines et ambiguïté
Les machines ne comprennent pas automatiquement les connexions contextuelles des mots nécessaires pour lever l'ambiguïté «banque» (rivière) et «banque» (institut financier). Encore moins, des mots polysémiques aux significations multiples nuancées, comme «obtenir» et «courir». Les machines perdent facilement la trace de qui parle dans les phrases, donc la résolution de la coréférence est également un défi majeur.
Lorsque le mot parlé tel que la recherche conversationnelle (et les homophones) entre dans le mélange, tout cela devient encore plus difficile, en particulier lorsque vous commencez à ajouter des phrases et des phrases ensemble.
Comment les moteurs de recherche apprennent la langue
Alors, comment les linguistes et les chercheurs des moteurs de recherche ont-ils permis aux machines de comprendre le sens sans ambiguïté des mots, des phrases et des phrases en langage naturel?
"Ce ne serait pas bien si Google comprenait le sens de votre phrase, plutôt que juste les mots qui sont dans la phrase?" a déclaré Eric Schmidt de Google en mars 2009, juste avant que la société n'annonce le déploiement de ses premières offres sémantiques.
Cela a marqué l'un des premiers abandons des «chaînes aux choses» et c'est peut-être l'avènement de l'implémentation de la recherche orientée entité par Google.
L'un des produits mentionnés dans la publication d'Eric Schmidt était des «choses liées» affichées dans les pages de résultats de recherche. Un exemple de «moment angulaire», de «relativité restreinte», de «big bang» et de «mécanique quantique» comme éléments connexes a été fourni.
Ces éléments pourraient être considérés comme des éléments concomitants qui vivent près les uns des autres en langage naturel par le biais de la «parenté». Les connexions sont relativement lâches, mais vous pouvez vous attendre à les trouver ensemble dans le contenu de la page Web.
Alors, comment les moteurs de recherche cartographient-ils ces «choses liées» ensemble?
Co-occurrence et similitude distributionnelle
En linguistique computationnelle, la cooccurrence est vraie l'idée que les mots ayant des significations similaires ou des mots apparentés ont tendance à vivre très près les uns des autres dans le langage naturel. En d'autres termes, ils ont tendance à être très proches dans les phrases et les paragraphes ou les corps de texte dans leur ensemble (parfois appelés corpus).
Ce domaine d'étude des relations et de la cooccurrence des mots est appelé linguistique firthienne , et ses racines sont généralement liées au linguiste des années 1950, John Firth , qui a déclaré:
"Vous connaîtrez un mot de la compagnie qu'elle tient."
(Firth, JR 1957)
Similitude et parenté
Dans la linguistique firthienne, les mots et les concepts vivant ensemble dans des espaces voisins dans le texte sont similaires ou liés.
On pense que des mots qui sont des «types de choses» similaires ont une similitude sémantique . Ceci est basé sur des mesures de la distance entre les concepts «isA» qui sont des concepts qui sont des types de «chose». Par exemple, une voiture et un bus ont une similitude sémantique car ce sont deux types de véhicules. La voiture et le bus pourraient combler le vide dans une phrase telle que:
«Un ____ est un véhicule», car les voitures et les bus sont des véhicules.
La parenté est différente de la similitude sémantique. La parenté est considérée comme une «similitude distributionnelle», car les mots liés aux entités isA peuvent fournir des indices clairs sur ce qu'est l'entité.
Par exemple, une voiture est similaire à un bus car ce sont deux véhicules, mais une voiture est liée aux concepts de «route» et de «conduite».
Vous pourriez vous attendre à trouver une voiture mentionnée dans une page sur la route et la conduite, ou dans une page assise à proximité (liée ou dans la section - catégorie ou sous-catégorie) une page sur une voiture.
Il s'agit d'une très bonne vidéo sur les notions de similitude et de parenté comme échafaudage pour le langage naturel .
Les humains comprennent naturellement cette co-occurrence comme faisant partie de la compréhension de bon sens, et elle a été utilisée dans l'exemple mentionné plus tôt autour de «banque» (rivière) et «banque» (institut financier).
Le contenu autour d'un sujet bancaire en tant qu'institut financier contiendra probablement des mots sur le thème de la finance plutôt que sur le thème des rivières ou de la pêche, ou sera lié à une page sur la finance.
Par conséquent, l'entreprise de la «banque» est la «finance», la «trésorerie», le «chèque», etc.
Graphiques de connaissances et référentiels
Chaque fois que la recherche sémantique et les entités sont mentionnées, nous pensons probablement immédiatement aux graphiques de connaissances des moteurs de recherche et aux données structurées, mais la compréhension du langage naturel n'est pas des données structurées.
Cependant, les données structurées facilitent la compréhension du langage naturel pour les moteurs de recherche grâce à la désambiguïsation via la similitude distributionnelle puisque la «société» d'un mot donne une indication quant aux sujets du contenu.
Les connexions entre les entités et leurs relations mappées à un graphe de connaissances et liées à des identifiants de concept uniques sont solides (par exemple, schéma et données structurées).
En outre, certaines parties de la compréhension des entités sont rendues possibles grâce au traitement du langage naturel, sous la forme d'une détermination d'entité (décider dans un corps de texte à laquelle de deux ou plusieurs entités du même nom sont référencées), car la reconnaissance d'entité n'est pas automatiquement sans ambiguïté.
La mention du mot «Mozart» dans un morceau de texte pourrait bien signifier «Mozart», le compositeur, le café «Mozart», la rue «Mozart», et il y a énormément de personnes et de lieux portant le même nom.
La majorité du Web n'est pas structurée du tout. Lorsque l'on considère l'ensemble du Web, même les données semi-structurées telles que les en-têtes sémantiques, les listes à puces et numérotées et les données tabulaires n'en constituent qu'une très petite partie. Il y a beaucoup de lacunes dans le texte ambigu et lâche des phrases, des phrases et des paragraphes.
Le traitement du langage naturel consiste à comprendre le texte non structuré lâche dans des phrases, des phrases et des paragraphes entre toutes ces «choses» qui sont «connues» (les entités). Une forme de «comblement des lacunes» dans le désordre chaud entre les entités. Similitude et parenté, et similitude distributionnelle) aident à cela.
La parenté peut être faible ou forte
Alors que les connexions de données entre les nœuds et les bords des entités et leurs relations sont fortes, la similitude est sans doute plus faible et la parenté encore plus faible. La parenté peut même être considérée comme vague.
Le lien de similitude entre les pommes et les poires en tant que choses «isA» est plus fort qu'un lien de parenté entre «peler», «manger», «cœur» à pomme, car cela pourrait facilement être un autre fruit qui est pelé et avec un cœur.
Une pomme n'est pas vraiment identifiée comme étant une «chose» claire ici simplement en voyant les mots «peler», «manger» et «cœur». Cependant, la parenté fournit des conseils pour affiner les types de «choses» à proximité dans le contenu.
Linguistique informatique
Une grande partie de la recherche sur le langage naturel «comblant des lacunes» pourrait être considérée comme une linguistique informatique; un domaine qui combine les mathématiques, la physique et le langage, en particulier l'algèbre linéaire et les vecteurs et les lois de puissance.
Le langage naturel et les fréquences de distribution ont globalement un certain nombre de phénomènes inexpliqués (par exemple, le mystère Zipf ), et il existe plusieurs articles sur «l'étrangeté» des mots et l'utilisation du langage.
Dans l'ensemble, cependant, une grande partie du langage peut être résolue par des calculs mathématiques autour de l'endroit où les mots cohabitent (l'entreprise qu'ils gardent), et cela constitue une grande partie de la façon dont les moteurs de recherche commencent à résoudre les défis du langage naturel (y compris la mise à jour BERT) .
Incorporation de mots et vecteurs de co-occurrence
En termes simples, les incorporations de mots sont une façon mathématique d'identifier et de regrouper dans un espace mathématique, des mots qui «vivent» les uns à côté des autres dans une collection de texte du monde réel, autrement connu comme un corpus de texte. Par exemple, le livre «Guerre et paix» est un exemple d'un grand corpus de texte, tout comme Wikipedia.
Les incorporations de mots ne sont que des représentations mathématiques de mots qui vivent généralement à proximité les uns des autres chaque fois qu'ils sont trouvés dans un corps de texte, mappés à des vecteurs (espaces mathématiques) utilisant des nombres réels.
Ces incorporations de mots prennent les notions de co-occurrence, de parenté et de similitude de distribution, les mots étant simplement mappés à leur entreprise et stockés dans des espaces vectoriels de co-occurrence. Les «nombres» vectoriels sont ensuite utilisés par les linguistes informaticiens dans un large éventail de tâches de compréhension du langage naturel pour essayer d'enseigner aux machines comment les humains utilisent le langage en fonction des mots qui vivent près les uns des autres.
Exemples de jeux de données WordSim353
Nous savons que les approches autour de la similitude et de la parenté avec ces vecteurs de cooccurrence et les incorporations de mots ont fait partie de la recherche menée par les membres de l'équipe de recherche en recherche conversationnelle de Google pour apprendre la signification des mots.
Par exemple, « Une étude sur la similitude et la parenté à l'aide d'approches distributionnelles et basées sur WordNet », qui utilise l'ensemble de données Wordsim353 pour comprendre la similitude distributionnelle.
Ce type de similitude et de parenté dans les ensembles de données est utilisé pour construire des «incorporations de mots» mappées à des espaces mathématiques (vecteurs) dans des corps de texte.
Voici un très petit exemple de mots qui se produisent généralement ensemble dans le contenu du jeu de données Wordsim353 , qui peut également être téléchargé au format Zip pour une exploration plus approfondie. Fourni par des correcteurs humains, le score dans la colonne de droite est basé sur la similitude des deux mots dans les colonnes de gauche et du milieu.
| argent | en espèces | 9.15 |
| côte | rive | 9.1 |
| argent | en espèces | 9.08 |
| argent | devise | 9.04 |
| Football | football | 9.03 |
| magicien | sorcier | 9.02 |
Word2Vec
Les approches d'apprentissage automatique semi-supervisées et non supervisées font désormais partie de ce processus d'apprentissage du langage naturel, qui a une linguistique informatique turbocompressée.
Les réseaux neuronaux sont formés pour comprendre les mots qui vivent à proximité les uns des autres afin d'obtenir des mesures de similitude et de parenté et de créer des incorporations de mots.
Ceux-ci sont ensuite utilisés dans des tâches de compréhension du langage naturel plus spécifiques pour enseigner aux machines comment les humains comprennent le langage.
Word2Vec de Google est un outil populaire pour créer ces espaces vectoriels de co-occurrence mathématique en utilisant du texte en entrée et des vecteurs en sortie . La sortie de Word2Vec peut créer un fichier vectoriel qui peut être utilisé sur de nombreux types de tâches de traitement du langage naturel.
Les deux principales méthodes d'apprentissage automatique de Word2Vec sont Skip-gram et Continuous Bag of Words.
Le modèle Skip-gram prédit les mots (contexte) autour du mot cible (cible), tandis que le modèle Continuous Bag of Words prédit le mot cible à partir des mots autour de la cible (contexte).
Ces modèles d'apprentissage non supervisés sont alimentés par paires de mots à travers une «fenêtre contextuelle» mobile avec un certain nombre de mots autour d'un mot cible. Le mot cible ne doit pas nécessairement se trouver au centre de la «fenêtre contextuelle» qui est composée d'un nombre donné de mots environnants, mais peut se trouver à gauche ou à droite de la fenêtre contextuelle.
Un point important à noter est que les fenêtres contextuelles mobiles sont unidirectionnelles. C'est-à-dire que la fenêtre se déplace sur les mots dans une seule direction, de gauche à droite ou de droite à gauche.
Marquage d'une partie du discours
Une autre partie importante de la linguistique informatique conçue pour enseigner le langage humain aux réseaux neuronaux concerne la mise en correspondance des mots dans les documents de formation avec différentes parties du discours. Ces parties du discours incluent les goûts des noms, des adjectifs, des verbes et des pronoms.
Les linguistes ont étendu les nombreuses parties du discours pour qu'elles soient de plus en plus fines, allant bien au-delà des parties courantes du discours que nous connaissons tous, telles que les noms, les verbes et les adjectifs.Ces parties étendues du discours incluent les goûts de VBP (Verbe , présent non singulier de la troisième personne), VBZ (verbe, présent singulier de la troisième personne) et PRP $ (pronom possessif).
La signification du mot sous forme de partie du discours peut être étiquetée en tant que partie du discours à l'aide d'un certain nombre de tagueurs avec une granularité variable de la signification du mot, par exemple, le Penn Treebank Tagger a 36 parties différentes d'étiquettes vocales et la partie CLAWS7 du discours tagger a un énorme 146 parties différentes de balises vocales.
Google Pygmalion , par exemple, qui est l'équipe de linguistes de Google, qui travaille sur la recherche conversationnelle et l'assistant, a utilisé une partie du balisage vocal dans le cadre de la formation de réseaux neuronaux pour la génération de réponses dans les extraits et la compression de phrases.
La compréhension de parties de discours dans une phrase donnée permet aux machines de commencer à comprendre le fonctionnement du langage humain, en particulier à des fins de recherche conversationnelle et de contexte conversationnel.
Pour illustrer, nous pouvons voir dans l'exemple de tagger «Part of Speech» ci-dessous, la phrase:
"Search Engine Land est une publication d'actualités de l'industrie de la recherche en ligne."
Ceci est étiqueté comme «nom / nom / nom / verbe / déterminant / adjectif / nom / nom / nom / nom» lorsqu'il est mis en évidence comme différentes parties du discours.

Problèmes avec les méthodes d'apprentissage des langues
Malgré tous les progrès des moteurs de recherche et des linguistes informaticiens, des approches non supervisées et semi-supervisées comme Word2Vec et Google Pygmalion présentent un certain nombre de lacunes qui empêchent une compréhension à grande échelle du langage humain.
Il est facile de voir comment ceux-ci freinaient certainement les progrès de la recherche conversationnelle.
Pygmalion est évolutif pour l'internationalisation
L'étiquetage des ensembles de données de formation avec des annotations marquées de parties du discours peut être à la fois long et coûteux pour toute organisation. De plus, les humains ne sont pas parfaits et il y a place à l'erreur et au désaccord. La partie du discours à laquelle un mot particulier appartient dans un contexte donné peut permettre aux linguistes de débattre entre eux pendant des heures.
L'équipe de linguistes de Google (Google Pygmalion) travaillant sur Google Assistant, par exemple, en 2016 était composée d'environ 100 doctorants. linguistes. Dans une interview avec Wired Magazine, Google Product Manager, David Orr a expliqué comment l'entreprise avait encore besoin de son équipe de doctorants. les linguistes qui étiquettent des parties du discours (appelant cela les données «d'or»), de manière à aider les réseaux neuronaux à comprendre le fonctionnement du langage humain.
Orr a dit de Pygmalion:
«L'équipe couvre entre 20 et 30 langues. Mais l'espoir est que des entreprises comme Google pourront éventuellement passer à une forme plus automatisée d'IA appelée «apprentissage non supervisé». »
En 2019, l'équipe Pygmalion était une armée de 200 linguistes à travers le monde composée d'un mélange de personnel permanent et d'agence , mais n'était pas sans défis en raison de la nature laborieuse et décourageante du travail d'étiquetage manuel et des longues heures nécessaires .
Dans le même article de Wired, Chris Nicholson, qui est le fondateur d'une société d'apprentissage en profondeur appelée Skymind, a commenté la nature non évolutive de projets comme Google Pygmalion, en particulier dans une perspective d'internationalisation, car une partie du balisage vocal devrait être effectuée. par les linguistes de toutes les langues du monde pour être véritablement multilingue.
Internationalisation de la recherche conversationnelle
Le marquage manuel impliqué dans Pygmalion ne semble pas prendre en compte les phénomènes naturels transférables de la linguistique informatique. Par exemple, la loi Zipfs, une loi de puissance de fréquence de distribution, dicte que dans n'importe quelle langue, la fréquence de distribution d'un mot est proportionnelle à une sur son rang, et cela est vrai même pour les langues non encore traduites.
Nature unidirectionnelle des «fenêtres de contexte» dans les RNN (réseaux de neurones récurrents)
Les modèles de formation tels que Skip-gram et Continuous Bag of Words sont unidirectionnels en ce sens que la fenêtre contextuelle contenant le mot cible et les mots contextuels qui l'entourent à gauche et à droite ne vont que dans une seule direction. Les mots après le mot cible ne sont pas encore vus, donc tout le contexte de la phrase est incomplet jusqu'au dernier mot, ce qui comporte le risque de manquer certains modèles contextuels.
Un bon exemple est fourni du défi des fenêtres contextuelles mobiles unidirectionnelles par Jacob Uszkoreit sur le blog de Google AI en parlant de l'architecture du transformateur.
Décider de la signification la plus probable et de la représentation appropriée du mot «banque» dans la phrase: «Je suis arrivé à la banque après avoir traversé le…» nécessite de savoir si la phrase se termine par «… route». ou "… rivière".

Cohésion du texte manquante
Les approches de formation unidirectionnelles empêchent la présence de cohésion de texte.
Comme Ludwig Wittgenstein, un philosophe a dit en 1953:
"Le sens d'un mot est son utilisation dans la langue."
(Wittgenstein, 1953)
Souvent, les petits mots et la façon dont les mots sont maintenus ensemble sont la «colle» qui apporte le bon sens dans le langage. Cette «colle» globale est appelée «cohésion du texte». C'est la combinaison des entités et des différentes parties du discours qui les entourent formulées ensemble dans un ordre particulier qui donne à une phrase une structure et un sens. L'ordre dans lequel un mot se trouve dans une phrase ou une phrase ajoute également à ce contexte.
Sans cette colle contextuelle de ces mots environnants dans le bon ordre, le mot lui-même n'a tout simplement pas de sens.
La signification du même mot peut également changer au fur et à mesure qu'une phrase ou une expression se développe en raison des dépendances des membres de la phrase ou de la phrase coexistants, changeant de contexte avec elle.
De plus, les linguistes peuvent ne pas être d'accord sur la partie de discours particulière dans un contexte donné à laquelle un mot appartient en premier lieu.
Prenons l'exemple du mot «seau». En tant qu'êtres humains, nous pouvons visualiser automatiquement un seau qui peut être rempli d'eau comme une «chose», mais il y a des nuances partout.
Que se passe-t-il si le mot mot seau était dans la phrase «Il a donné un coup de pied dans le seau» ou «Je n'ai pas encore rayé cela de ma liste de seaux?» Soudain, le mot prend un tout nouveau sens. Sans la cohésion textuelle des mots qui l'accompagnent et souvent minuscules autour de «seau», nous ne pouvons pas savoir si le seau fait référence à un outil porteur d'eau ou à une liste d'objectifs de vie.
Les incorporations de mots sont sans contexte
Le modèle d'incorporation de mots fourni par des personnes comme Word2Vec connaît les mots en quelque sorte ensemble, mais ne comprend pas dans quel contexte ils doivent être utilisés. Le vrai contexte n'est possible que lorsque tous les mots d'une phrase sont pris en considération. Par exemple, Word2Vec ne sait pas quand la rivière (rive) est le bon contexte ou la banque (dépôt). Alors que des modèles ultérieurs tels que ELMo formés à la fois sur le côté gauche et le côté droit d'un mot cible, ceux-ci ont été effectués séparément plutôt que de regarder tous les mots (à gauche et à droite) simultanément, et ne fournissaient toujours pas le vrai contexte .
Polysémie et homonymie mal gérées
Les incorporations de mots comme Word2Vec ne gèrent pas correctement la polysémie et les homonymes. Comme un seul mot avec plusieurs significations est mappé sur un seul vecteur. Il est donc nécessaire de lever les ambiguïtés. Nous savons qu'il existe de nombreux mots ayant la même signification (par exemple, «courir» avec 606 significations différentes), donc c'était une lacune. Comme illustré précédemment, la polysémie est particulièrement problématique car les mots polysémiques ont les mêmes origines racines et sont extrêmement nuancés.
Résolution de la coréférence toujours problématique
Les moteurs de recherche étaient toujours aux prises avec le problème difficile de la résolution des anaphores et des cataphores, qui était particulièrement problématique pour la recherche conversationnelle et l'assistant, qui peuvent avoir des questions et réponses à plusieurs tours.
Il est essentiel de pouvoir suivre les entités auxquelles il est fait référence pour ces types de requêtes vocales.
Pénurie de données de formation
Les modèles modernes de PNL basés sur l'apprentissage en profondeur apprennent mieux lorsqu'ils sont formés sur d'énormes quantités d'exemples de formation annotés, et un manque de données de formation était un problème courant qui freinait le domaine de la recherche dans son ensemble.
Alors, comment le BERT aide-t-il à améliorer la compréhension du langage des moteurs de recherche?
Compte tenu de ces lacunes ci-dessus, comment le BERT a-t-il aidé les moteurs de recherche (et d'autres chercheurs) à comprendre la langue?
Qu'est-ce qui rend BERT si spécial?
Il y a plusieurs éléments qui rendent l'ORET si spécial pour la recherche et au-delà (le monde - oui, il est aussi grand qu'une fondation de recherche pour le traitement du langage naturel). Plusieurs des caractéristiques spéciales peuvent être trouvées dans le titre papier du BERT - BERT: Représentations des codeurs bidirectionnels des transformateurs.
B - Bi-directionnel
E - Encodeur
R - Représentations
T - Transformateurs
Mais le BERT apporte également d'autres développements passionnants dans le domaine de la compréhension du langage naturel.
Ceux-ci inclus:
- Pré-formation à partir d'un texte non étiqueté
- Modèles contextuels bidirectionnels
- L'utilisation d'une architecture de transformateur
- Modélisation du langage masqué
- Attention focalisée
- Implication textuelle (prédiction de la phrase suivante)
- Désambiguïsation grâce au contexte open source
Pré-formation à partir de texte sans étiquette
La `` magie '' du BERT est sa mise en œuvre d'une formation bidirectionnelle sur un corpus de texte non étiqueté, car depuis de nombreuses années dans le domaine de la compréhension du langage naturel, les collections de textes ont été balisées manuellement par des équipes de linguistes attribuant à chaque partie diverses parties du discours. mot.
BERT a été le premier framework / architecture de langage naturel à être pré-formé en utilisant un apprentissage non supervisé sur du texte brut pur (2,5 milliards de mots + de Wikipedia anglais) plutôt que sur des corpus étiquetés.
Les modèles antérieurs avaient exigé un étiquetage manuel et la construction de représentations distribuées des mots (incorporations de mots et vecteurs de mots), ou avaient besoin d'une partie des marqueurs de discours pour identifier les différents types de mots présents dans un corps de texte. Ces approches passées sont similaires au marquage que nous avons mentionné précédemment par Google Pygmalion.
Le BERT apprend la langue en comprenant la cohésion du texte à partir de ce grand corps de contenu en texte brut et est ensuite éduqué en affinant des tâches de langage naturel plus petites et plus spécifiques. Le BERT s'auto-apprend également avec le temps.
Modèles contextuels bidirectionnels
BERT est le premier modèle de langage naturel profondément bidirectionnel, mais qu'est-ce que cela signifie?
Modélisation bidirectionnelle et unidirectionnelle
La véritable compréhension contextuelle vient de la possibilité de voir tous les mots d'une phrase en même temps et de comprendre comment tous les mots ont un impact sur le contexte des autres mots de la phrase.
La partie du discours à laquelle un mot particulier appartient peut littéralement changer à mesure que la phrase se développe.
Par exemple, bien qu'il soit peu probable qu'il s'agisse d'une requête, si nous prenons une phrase parlée qui pourrait bien apparaître dans une conversation naturelle (quoique rarement):
"J'aime la façon dont vous aimez ça, il aime ça."
au fur et à mesure que la phrase développe la partie du discours à laquelle le mot «comme» se rapporte lorsque le contexte se construit autour de chaque mention du mot change de sorte que le mot «comme», bien que textuellement soit le même mot, dépend contextuellement des différentes parties du discours sa place dans la phrase ou la phrase.
Les anciens modèles de formation en langage naturel ont été formés de manière unidirectionnelle. La signification du mot dans une fenêtre contextuelle s'est déplacée de gauche à droite ou de droite à gauche avec un nombre donné de mots autour du mot cible (le contexte du mot ou «c'est la société»). Cela signifie que les mots qui ne sont pas encore vus dans leur contexte ne peuvent pas être pris en considération dans une phrase et qu'ils pourraient en fait changer le sens d'autres mots en langage naturel. Les fenêtres contextuelles mobiles unidirectionnelles peuvent donc manquer certains contextes changeants importants.
Par exemple, dans la phrase:
"Dawn, comment vas-tu?"
Le mot «are» pourrait être le mot cible et le contexte de gauche de «are» est «Dawn, how». Le bon contexte du mot est «vous».
L'ORET est capable de regarder les deux côtés d'un mot cible et la phrase entière simultanément de la même manière que les humains regardent le contexte entier d'une phrase plutôt que d'en regarder seulement une partie. La phrase entière, à la fois à gauche et à droite d'un mot cible, peut être considérée simultanément dans le contexte.
Transformateurs / Architecture des transformateurs
La plupart des tâches de compréhension du langage naturel reposent sur des prédictions de probabilité. Quelle est la probabilité que cette phrase se rapporte à la phrase suivante, ou quelle est la probabilité que ce mot fasse partie de cette phrase? L'architecture du BERT et les systèmes de prédiction de modélisation du langage masqué sont en partie conçus pour identifier les mots ambigus qui changent la signification des phrases et des phrases et identifier la bonne. Les apprentissages sont de plus en plus transmis par les systèmes du BERT.
Le transformateur utilise la fixation sur les mots dans le contexte de tous les autres mots dans des phrases ou des phrases sans lesquelles la phrase pourrait être ambiguë.
Cette attention fixe vient d'un article intitulé `` L'attention est tout ce dont vous avez besoin '' (Vaswani et al, 2017), publié un an plus tôt que le document de recherche BERT, avec l'application transformateur intégrée dans la recherche BERT.
Essentiellement, le BERT est capable de regarder tout le contexte dans la cohésion du texte en concentrant l'attention sur un mot donné dans une phrase tout en identifiant également tout le contexte des autres mots par rapport au mot. Ceci est réalisé simultanément en utilisant des transformateurs combinés avec une pré-formation bidirectionnelle.
Cela contribue à un certain nombre de défis linguistiques de longue date pour la compréhension du langage naturel, y compris la résolution de coréférence. Cela est dû au fait que les entités peuvent être ciblées dans une phrase en tant que mot cible et que leurs pronoms ou les phrases nominales les référençant sont résolus de nouveau vers l'entité ou les entités dans la phrase ou l'expression.
De cette façon, les concepts et le contexte de qui, ou quoi, une phrase particulière se rapporte spécifiquement, ne sont pas perdus en cours de route.
De plus, l'attention focalisée aide également à la désambiguïsation des mots polysémiques et des homonymes en utilisant une prédiction / pondération de probabilité basée sur le contexte entier du mot en contexte avec tous les autres mots de la phrase. Les autres mots reçoivent un score d'attention pondéré pour indiquer combien chacun ajoute au contexte du mot cible en tant que représentation du «sens». Les mots d'une phrase sur la «banque» qui ajoutent un contexte fortement ambigu comme le «dépôt» auraient plus de poids dans une phrase sur la «banque» (institut financier) pour résoudre le contexte de représentation à celui d'un institut financier.
La partie représentations du codeur du nom BERT fait partie de l'architecture du transformateur. L'encodeur est l'entrée de phrase traduite en représentations de sens des mots et le décodeur est la sortie de texte traitée sous une forme contextualisée.
Dans l'image ci-dessous, nous pouvons voir que «il» est fortement lié à «l'animal» et à «l'animal» pour résoudre la référence à «l'animal» comme «il» comme une résolution d'anaphora.

Cette fixation aide également à changer la «partie du discours» que pourrait avoir l'ordre d'un mot dans une phrase, car nous savons que le même mot peut être différentes parties du discours selon son contexte.
L'exemple fourni par Google ci-dessous illustre l'importance des différentes parties du discours et de la désambiguïsation des catégories de mots. Bien qu'il s'agisse d'un petit mot, le mot «à» change ici complètement le sens de la requête une fois qu'elle est prise en considération dans le contexte complet de la phrase ou de la phrase.

Modélisation du langage masqué (formation MLM)
Également connue sous le nom de «procédure Cloze» qui existe depuis très longtemps. L'architecture BERT analyse les phrases avec certains mots masqués de manière aléatoire et tente de prédire correctement ce qu'est le mot «caché».
Le but de ceci est d'empêcher les mots cibles dans le processus d'apprentissage passant par l'architecture du transformateur BERT de se voir par inadvertance pendant l'entraînement bidirectionnel lorsque tous les mots sont examinés ensemble pour un contexte combiné. C'est à dire. cela évite un type de boucle infinie erronée dans l'apprentissage automatique du langage naturel, qui fausserait le sens du mot.
Implication textuelle (prédiction de la phrase suivante)
L'une des principales innovations du BERT est qu'il est censé être capable de prédire ce que vous allez dire ensuite, ou, comme le New York Times l'a exprimé en octobre 2018, « enfin, une machine qui peut terminer vos phrases ».
L'ORET est formé pour prédire à partir de paires de phrases si la deuxième phrase fournie correspond bien à un corpus de texte.
NB: Il semble que cette fonctionnalité au cours de l'année écoulée ait été jugée non fiable dans le modèle BERT d'origine et d'autres offres open source ont été conçues pour résoudre cette faiblesse. ALBERT de Google résout ce problème.
L'implication textuelle est un type de "qu'est-ce qui vient ensuite?" dans un corps de texte. En plus de l'implication textuelle, le concept est également connu sous le nom de «prédiction de la phrase suivante». L'implication textuelle est une tâche de traitement du langage naturel impliquant des paires de phrases. La première phrase est analysée, puis un niveau de confiance déterminé pour prédire si une deuxième phrase hypothétique donnée dans la paire «correspond» logiquement à la phrase suivante appropriée, ou non, avec une prédiction positive, négative ou neutre, à partir d'un texte collection sous examen.
Ci-dessous, trois exemples tirés de Wikipédia de chaque type de prédiction d'implication textuelle (neutre / positif / négatif). Exemples d'implication textuelle (Source: Wikipedia)
Un exemple d'un TE positif (le texte implique une hypothèse) est:
texte: Si vous aidez les nécessiteux, Dieu vous récompensera.
hypothèse: Donner de l'argent à un pauvre a de bonnes conséquences .
Un exemple d'un TE négatif (le texte contredit l'hypothèse) est:
texte: Si vous aidez les nécessiteux, Dieu vous récompensera.
hypothèse: Donner de l'argent à un pauvre n'a pas de conséquences.
Un exemple de non-TE (le texte n'implique ni ne contredit) est:
texte: Si vous aidez les nécessiteux, Dieu vous récompensera.
hypothèse: Donner de l'argent à un pauvre homme fera de vous une meilleure personne.
Des percées sans ambiguïté grâce aux contributions ouvertes
BERT n'est pas seulement apparu de nulle part, et BERT n'est pas non plus une mise à jour algorithmique ordinaire car BERT est également un cadre de compréhension du langage naturel open source.
Une «désambiguïsation révolutionnaire par rapport au contexte, renforcée par des contributions ouvertes», pourrait être utilisée pour résumer la principale valeur ajoutée du BERT à la compréhension du langage naturel. En plus d'être le plus grand changement du système de recherche de Google en cinq ans (ou jamais), le BERT représente probablement le plus grand pas en avant dans la compréhension contextuelle croissante du langage naturel par les ordinateurs de tous les temps.
Bien que Google BERT puisse être nouveau dans le monde du référencement, il est bien connu dans le monde NLU en général et a suscité beaucoup d'enthousiasme au cours des 12 derniers mois. Le BERT a fourni une amélioration du bâton de hockey à travers de nombreux types de tâches de compréhension du langage naturel non seulement pour Google, mais une myriade de chercheurs industriels et universitaires cherchant à utiliser la compréhension du langage dans leur travail, et même des applications commerciales.
Après la publication du document de recherche du BERT, Google a annoncé qu'il serait open source BERT vanilla. Au cours des 12 mois qui ont suivi la publication, le document original du BERT a été cité dans de nouvelles recherches 1 997 fois à la date de rédaction.
Il existe de nombreux types de modèles BERT différents, qui vont bien au-delà des limites de la recherche Google.
Une recherche de Google BERT dans Google Scholar renvoie des centaines d'entrées de documents de recherche publiés en 2019 s'étendant sur le BERT de nombreuses façons, le BERT étant désormais utilisé dans toutes sortes de recherches sur le langage naturel.
Les articles de recherche traversent un mélange éclectique de tâches langagières, de domaines verticaux (par exemple les domaines cliniques), de types de médias (vidéo, images) et dans plusieurs langues. Les cas d'utilisation du BERT sont d'une grande portée, allant de l'identification de tweets offensants à l'aide de BERT et SVM à l'utilisation de BERT et CNN pour la détection des trolls russes sur Reddit , à la catégorisation via des films de prédiction selon l'analyse des sentiments de l'IMDB, ou à la prédiction de la phrase suivante dans une question et une réponse. paire dans le cadre d'un ensemble de données.
Grâce à cette approche open-source, le BERT va un long chemin vers la résolution de certains problèmes linguistiques de longue date dans la recherche, en fournissant simplement une base solide à affiner pour toute personne désireuse de le faire. La base de code est téléchargeable à partir de la page Github de l'équipe de recherche Google.
En fournissant Vanilla BERT comme un tremplin idéal pour les amateurs de machine learning, Google a aidé à repousser les limites des tâches de compréhension du langage naturel de pointe (SOTA). Vanilla BERT peut être comparé à des plugins, un thème ou un module CMS qui fournit une base solide pour une fonctionnalité particulière, mais peut ensuite être développé. Une autre similitude plus simple pourrait être de comparer les parties de pré-formation et de réglage fin de BERT pour les ingénieurs d'apprentissage automatique à l'achat d'un costume prêt à l'emploi dans un magasin de haute rue, puis de visiter un tailleur pour retrousser les ourlets afin qu'il soit adapté à l'usage à un niveau de besoins plus unique.
Comme Vanilla BERT est pré-formé (sur Wikipedia et Brown corpus), les chercheurs n'ont qu'à affiner leurs propres modèles et paramètres supplémentaires par-dessus le modèle déjà formé en quelques époques (boucles / itérations à travers le modèle de formation avec le nouveau éléments affinés inclus).
Au moment du BERT en octobre 2018, la publication papier BERT battait l'état de l'art (SOTA) par rapport à 11 types différents de tâches de compréhension du langage naturel, y compris les questions et réponses, l'analyse des sentiments, la détermination des entités nommées, la classification et l'analyse des sentiments, la paire de phrases - l'appariement et l'inférence du langage naturel.
En outre, BERT a peut-être commencé comme le cadre de langage naturel de pointe, mais très rapidement d'autres chercheurs, y compris certains d'autres grandes sociétés axées sur l'IA telles que Microsoft, IBM et Facebook, ont pris BERT et l'ont étendu pour produire leurs propres contributions open source battant tous les records. Par la suite, des modèles autres que BERT sont devenus à la pointe de la technologie depuis la sortie de BERT.
Liu et al de Facebook sont entrés dans le BERTathon avec leur propre version s'étendant sur BERT - RoBERTa. affirmant que le BERT d'origine était considérablement sous-formé et prétend avoir amélioré et battu toutes les autres versions de modèle de BERT jusqu'à ce point.
Microsoft a également battu le BERT d'origine avec MT-DNN , prolongeant un modèle qu'ils avaient proposé en 2015 mais ajoutant l'architecture de pré-formation bidirectionnelle du BERT pour continuer à s'améliorer.

Il existe également de nombreux autres modèles basés sur BERT, notamment le propre XLNet et ALBERT de Google (Toyota et Google), le BERT-mtl d'IBM et même maintenant le Google T5 qui émerge.
Le domaine est extrêmement compétitif et les équipes d'ingénieurs d'apprentissage automatique NLU rivalisent entre elles et avec des référentiels de compréhension humaine non experts dans les classements publics, ajoutant un élément de gamification au domaine.
Parmi les classements les plus populaires figurent le très compétitif SQuAD et le GLUE.
SQuAD signifie The Stanford Question and Answering Dataset qui est construit à partir de questions basées sur des articles Wikipedia avec des réponses fournies par des travailleurs de foule.
La version actuelle SQuAD 2.0 de l'ensemble de données est la deuxième itération créée parce que SQuAD 1.1 a été presque battu par les chercheurs en langage naturel. Le jeu de données de deuxième génération, SQuAD 2.0, représentait un jeu de données plus difficile et contenait également un nombre intentionnel de questions contradictoires dans le jeu de données (questions pour lesquelles il n'y avait pas de réponse). La logique derrière cette inclusion de questions contradictoires est intentionnelle et conçue pour former des modèles à apprendre ce qu'ils ne savent pas (c'est-à-dire une question sans réponse).
GLUE est l'ensemble de données et le classement du General Language Understanding Evaluation. SuperGLUE est la deuxième génération de GLUE créée parce que GLUE est redevenue trop facile à battre pour les modèles d'apprentissage automatique.

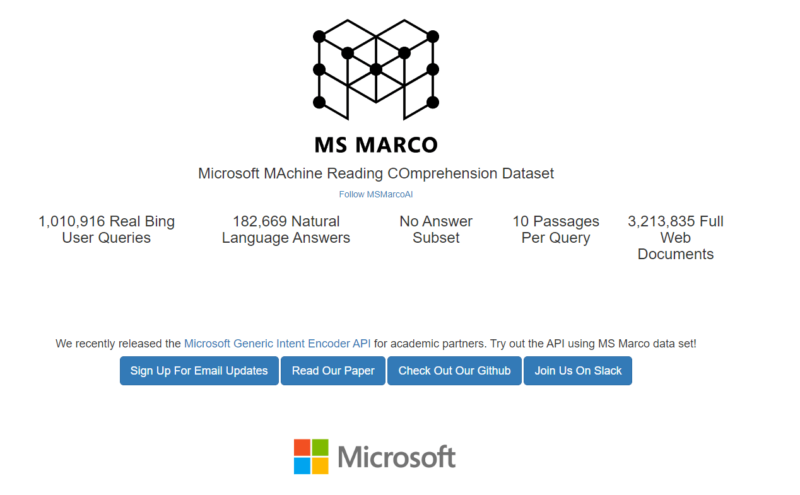
La plupart des classements publics dans le domaine de l'apprentissage automatique se transforment en articles académiques accompagnés de riches ensembles de données de questions et réponses pour que les concurrents affinent leurs modèles. MS MARCO, par exemple, est un document académique, un ensemble de données et un classement connexe publié par Microsoft; AKA Microsoft MAchine Reading COmprehension Dataset.
L'ensemble de données MSMARCO est composé de plus d'un million de requêtes utilisateur Bing réelles et de plus de 180 000 réponses en langage naturel. Tous les chercheurs peuvent utiliser cet ensemble de données pour affiner les modèles.
Efficacité et dépenses de calcul
La fin de 2018 à 2019 peut être considérée comme une année de furieux saut de classement public pour créer le modèle actuel d'apprentissage automatique en langage naturel.
Au fur et à mesure que la course pour atteindre le sommet des différents classements de pointe s'est intensifiée, la taille des ingénieurs en apprentissage automatique du modèle a également augmenté et le nombre de paramètres ajoutés en fonction de la conviction que plus de données augmentent la probabilité d'une plus grande précision. Cependant, à mesure que la taille des modèles augmentait, la taille des ressources nécessaires pour le réglage fin et la formation continue augmentait, ce qui était clairement une voie open source non durable.
Victor Sanh, de Hugging Face (une organisation qui cherche à promouvoir la démocratie continue de l'intelligence artificielle) écrit , au sujet de l'augmentation drastique de la taille des nouveaux modèles:
«Le dernier modèle de Nvidia a 8,3 milliards de paramètres: 24 fois plus grand que BERT-large, 5 fois plus grand que GPT-2, tandis que RoBERTa, le dernier travail de Facebook AI, a été formé sur 160 Go de texte 😵»
Pour illustrer les tailles BERT d'origine - BERT-Base et BERT-Large, avec 3 fois le nombre de paramètres de BERT-Base.
BERT - Base , boîtier: 12 couches, 768 masqués, 12 têtes, paramètres 110M. BERT - Large , avec boîtier: 24 couches, 1024 masqués, 16 têtes, 340 millions de paramètres.
L'escalade des coûts et de la taille des données a nécessité la construction de modèles plus efficaces, moins coûteux en termes de calcul et de coûts.
Bienvenue à Google ALBERT, Hugging Face DistilBERT et FastBERT
ALBERT de Google, sorti en septembre 2019, est un travail conjoint entre Google AI et l'équipe de recherche de Toyota. ALBERT est considéré comme le successeur naturel du BERT car il atteint également des scores de pointe dans un certain nombre de tâches de traitement du langage naturel, mais est capable de les réaliser de manière beaucoup plus efficace et moins coûteuse en termes de calcul.
Large ALBERT a 18 fois moins de paramètres que BERT-Large. L'une des principales innovations marquantes avec ALBERT sur BERT est également un correctif d'une tâche de prédiction de la phrase suivante qui s'est avérée peu fiable car BERT a été examiné de près dans l'espace open source tout au long de l'année.
Nous pouvons voir ici au moment de la rédaction, sur SQuAD 2.0 que ALBERT est le modèle SOTA actuel ouvrant la voie. ALBERT est plus rapide et plus léger que le BERT d'origine et atteint également l'état de l'art (SOTA) sur un certain nombre de tâches de traitement du langage naturel.

Les autres modèles de type BERT à échelle réduite et axés sur l'efficacité et le budget récemment introduits sont DistilBERT , censé être plus petit, plus léger, moins cher et plus rapide, et FastBERT .
Alors, que signifie BERT pour le référencement?
Le BERT peut être connu des référenceurs comme une mise à jour algorithmique, mais en réalité, c'est plus «l'application» d'un système multicouche qui comprend les nuances polysémiques et est mieux en mesure de résoudre les co-références sur les «choses» en langage naturel continuellement fines. -un réglage par auto-apprentissage.
L'objectif de BERT est d'améliorer la compréhension du langage humain pour les machines. Dans une perspective de recherche, cela pourrait être dans des requêtes écrites ou parlées émises par les utilisateurs des moteurs de recherche, et dans les moteurs de recherche de contenu se rassemblent et indexent. L'ORET en recherche consiste principalement à résoudre l'ambiguïté linguistique dans le langage naturel. BERT fournit une cohésion de texte qui vient souvent des petits détails d'une phrase qui donne de la structure et du sens.
BERT n'est pas une mise à jour algorithmique comme Penguin ou Panda, car BERT ne juge pas les pages Web de manière négative ou positive, mais améliore davantage la compréhension du langage humain pour la recherche Google. Par conséquent, Google comprend beaucoup plus la signification du contenu sur les pages qu'il rencontre et les questions que les utilisateurs émettent en tenant compte du contexte complet de Word.
BERT concerne les phrases et les expressions
L'ambiguïté n'est pas au niveau d'un mot, mais au niveau d'une phrase, car il s'agit de la combinaison de mots avec des significations multiples qui provoquent une ambiguïté.

BERT aide à la résolution polysémique
Google BERT aide la recherche Google à comprendre la «cohésion du texte» et à lever l'ambiguïté dans les phrases et les phrases, en particulier lorsque les nuances polysémiques peuvent changer la signification contextuelle des mots.
En particulier, la nuance de mots polysémiques et d'homonymes avec des significations multiples, telles que «à», «deux», «à», et «stand» et «stand», comme fourni dans les exemples de Google, illustrent la nuance qui avait précédemment été raté ou mal interprété dans la recherche.
Requêtes ambiguës et nuancées impactées
Les 10% des requêtes de recherche sur lesquelles le BERT aura un impact peuvent être très nuancées, impactées par l'amélioration de la cohésion contextuelle de la cohésion du texte et de la désambiguïsation. En outre, cela pourrait bien avoir un impact sur la compréhension de 15% des nouvelles requêtes que Google voit chaque jour, dont beaucoup concernent des événements du monde réel et des requêtes floues / temporelles plutôt que de simples requêtes à longue queue.
Rappel et précision impactés (impressions?)
La précision dans la réunion de requête ambiguë sera probablement considérablement améliorée, ce qui peut signifier que l'expansion de requête et la relaxation pour inclure plus de résultats (rappel) peuvent être réduites.
La précision est une mesure de la qualité des résultats, tandis que le rappel concerne simplement le retour de toutes les pages qui peuvent être pertinentes pour une requête.
Nous pouvons voir cette réduction du rappel se refléter dans le nombre d'impressions que nous voyons dans Google Search Console, en particulier pour les pages avec un contenu long qui pourraient actuellement être en rappel pour les requêtes pour lesquelles elles ne sont pas particulièrement pertinentes.
BERT aidera à la résolution de la coréférence
Les capacités de BERT (le document de recherche et le modèle de langage) avec une résolution de coréférence signifient que l'algorithme de Google aide probablement la recherche Google à garder une trace des entités lorsque les pronoms et les phrases nominales s'y réfèrent.
Le mécanisme d'attention du BERT est capable de se concentrer sur l'entité sous le focus et de résoudre toutes les références dans les phrases et les phrases en utilisant une détermination / score de probabilité.
Les pronoms de «il», «elle», «eux», «il» et ainsi de suite seront beaucoup plus faciles pour Google à cartographier à la fois dans le contenu et les requêtes, parlées et écrites.
Cela peut être particulièrement important pour les paragraphes plus longs avec plusieurs entités référencées dans le texte pour la génération d'extraits en vedette et l'extraction de réponses de recherche vocale / recherche conversationnelle.
Le BERT sert une multitude de buts
Google BERT est probablement ce qui pourrait être considéré comme un outil de type couteau suisse pour la recherche Google.
Le BERT fournit une base linguistique solide pour la recherche Google pour ajuster et ajuster en permanence les poids et les paramètres, car il existe de nombreux types de tâches de compréhension du langage naturel qui pourraient être entreprises.
Les tâches peuvent comprendre:
- Résolution de la coréférence (garder une trace de qui, ou quoi, une phrase ou une phrase fait référence dans le contexte ou une requête conversationnelle approfondie)
- Résolution de la polysémie (gestion des nuances ambiguës)
- Résolution d'homonymes (traiter la compréhension de mots qui sonnent de la même façon, mais signifient des choses différentes
- Détermination d'entité nommée (comprendre à laquelle, à partir d'un certain nombre d'entités nommées, le texte se rapporte puisque la reconnaissance d'entité nommée n'est pas la détermination d'entité nommée ou la désambiguïsation), ou l'une des nombreuses autres tâches.
- Implication textuelle (prédiction de la phrase suivante)
BERT sera énorme pour la recherche conversationnelle et l'assistant
Attendez-vous à un bond en avant en termes de pertinence par rapport à la recherche conversationnelle alors que le modèle en pratique de Google continue de s'enseigner avec plus de requêtes et de paires de phrases.
Il est probable que ces sauts quantiques ne seront pas seulement dans la langue anglaise, mais très bientôt, dans les langues internationales également, car il y a un élément d'apprentissage à action directe au sein du BERT qui semble être transféré dans d'autres langues.
Le BERT aidera probablement Google à étendre la recherche conversationnelle
Attendez-vous à court et moyen terme à un bond en avant quant à l'application à la recherche vocale, car la lourde tâche de développer la compréhension de la langue retenue par le processus manuel de Pygmalion pourrait ne plus être.
L'article de Wired de 2016 précédemment référencé se terminait par une définition de l'apprentissage automatisé et non supervisé de l'IA qui pourrait remplacer Google Pygmalion et créer une approche évolutive pour former les réseaux neuronaux:
«C'est à ce moment-là que les machines apprennent à partir de données non étiquetées - d'énormes quantités d'informations numériques extraites d'Internet et d'autres sources.»
(Filaire, 2016)
Cela ressemble à Google BERT.
Nous savons également que des extraits en vedette ont également été créés par Pygmalion.
Bien qu'il ne soit pas clair si BERT aura un impact sur la présence et la charge de travail de Pygmalion, ni si les extraits de code seront générés de la même manière que précédemment, Google a annoncé que BERT sera utilisé pour les extraits de fonction et est pré-formé sur un texte purement volumineux corpus.
En outre, la nature d'auto-apprentissage d'une fondation de type BERT alimentée en permanence et en récupérant des réponses et des extraits de contenu transmettra naturellement les apprentissages et deviendra encore plus affinée.
Le BERT pourrait donc fournir une alternative potentiellement extrêmement évolutive au travail laborieux de Pygmalion.
Le référencement international peut également bénéficier de façon spectaculaire
L'un des impacts majeurs du BERT pourrait être dans le domaine de la recherche internationale, car les apprentissages que le BERT apprend dans une langue semblent également avoir une certaine valeur transférable dans d'autres langues et domaines.
Hors de la boîte, BERT semble avoir quelques propriétés multilingues dérivées d'une manière ou d'une autre d'un corpus monolingue (compréhension d'une seule langue) puis étendu à 104 langues, sous la forme de M-BERT (Multilingual BERT).
Un article de Pires, Schlinger & Garrette a testé les capacités multilingues de Multilingual BERT et a constaté qu'il «était étonnamment bon pour le transfert de modèle multilingue sans coup de feu ». (Pires, Schlinger et Garrette, 2019). Cela s'apparente presque à être capable de comprendre un langage que vous n'avez jamais vu auparavant, car l'apprentissage à zéro vise à aider les machines à classer les objets qu'ils n'ont jamais vus auparavant.
Questions et réponses
Les questions et les réponses directement dans les SERP continueront probablement d'être plus précises, ce qui pourrait entraîner une réduction supplémentaire du nombre de clics vers les sites.
De la même manière que MSMARCO est utilisé pour le réglage fin et est un véritable ensemble de données de questions et réponses humaines des utilisateurs de Bing, Google continuera probablement à affiner son modèle dans la recherche réelle au fil du temps grâce à des requêtes humaines réelles et à des réponses transmettre les apprentissages.
Comme la langue continue d'être comprise, la compréhension des paraphrases améliorée par Google BERT peut également avoir un impact sur les requêtes associées dans "Les gens demandent aussi".
Implication textuelle (prédiction de la phrase suivante)
Les allers-retours de la recherche conversationnelle et les questions et réponses à plusieurs tours pour l'assistant bénéficieront également considérablement de la fonctionnalité de «textual implailment» (prédiction de la phrase suivante) de BERT, en particulier la capacité de prédire «ce qui vient ensuite» dans un scénario d'échange de requêtes . Cependant, cela pourrait ne pas apparaître aussi rapidement que certains des impacts initiaux du BERT.
De plus, comme le BERT peut comprendre différentes significations pour les mêmes choses dans les phrases, aligner les requêtes formulées d'une manière et les résoudre en réponses qui équivalent à la même chose sera beaucoup plus facile.
J'ai demandé au Dr Mohammad Aliannejadi quelle était la valeur du BERT pour la recherche de recherche conversationnelle. Le Dr Aliannejadi est un chercheur en recherche d'informations qui a récemment soutenu son doctorat. travaux de recherche sur la recherche conversationnelle, supervisés par le professeur Fabio Crestani , l'un des auteurs de « Mobile information retrieval ».
Une partie des travaux de recherche du Dr Aliannejadi a exploré les effets de poser des questions de clarification pour les assistants conversationnels et a utilisé le BERT dans sa méthodologie.
Le Dr Aliannejadi a parlé de la valeur du BERT:
«L'ORET représente la phrase entière, et donc il représente le contexte de la phrase et peut modéliser la relation sémantique entre deux phrases. L'autre fonctionnalité puissante est la possibilité de le régler avec précision en quelques époques seulement. Donc, vous avez un outil général et ensuite le rendre spécifique à votre problème. "
Détermination de l'entité nommée
L'une des tâches de traitement du langage naturel entreprises par des personnes comme un modèle BERT affiné pourrait être la détermination d'entité. La détermination de l'entité détermine la probabilité qu'une entité nommée particulière soit référencée à partir de plus d'un choix d'entité nommée portant le même nom.
La reconnaissance d'entité nommée n'est pas une désambiguïsation d'entité nommée ni une détermination d'entité nommée.
Dans une AMA sur Reddit, Gary Illyes de Google a confirmé que les mentions non liées de noms de marque peuvent actuellement être utilisées à des fins de détermination d'entité nommée.
L'ORET aidera à comprendre quand une entité nommée est reconnue mais pourrait être l'une des nombreuses entités nommées portant le même nom les unes que les autres.
Un exemple de plusieurs entités nommées avec le même nom est dans l'exemple ci-dessous. Bien que ces entités puissent être reconnues par leur nom, elles doivent être désambiguïsées l'une de l'autre. Potentiellement, un domaine BERT peut vous aider.
Nous pouvons voir à partir d'une recherche sur Wikipedia ci-dessous que le mot «Harris» renvoie de nombreuses entités nommées appelées «Harris».

BERT pourrait être BERT par son nom, mais pas par nature
Il n'est pas clair si la mise à jour de Google BERT utilise le BERT d'origine ou l'ALBERT beaucoup plus maigre et peu coûteux, ou une autre variante hybride des nombreux modèles maintenant disponibles, mais comme ALBERT peut être affiné avec beaucoup moins de paramètres que BERT, cela pourrait avoir du sens .
Cela pourrait bien signifier que l'algorithme BERT dans la pratique peut ne pas ressembler du tout au BERT d'origine dans le premier article publié, mais une version améliorée plus récente qui ressemble beaucoup plus aux efforts d'ingénierie (également open source) d'autres visant à construire les derniers modèles SOTA.
BERT peut être une version de production à grande échelle entièrement repensée, ou une version plus économique et améliorée de BERT, comme le travail conjoint de Toyota et Google, ALBERT.
De plus, BERT peut continuer d'évoluer vers d'autres modèles, car l'équipe Google T5 a également un modèle sur les classements publics SuperGLUE appelé simplement T5.
BERT peut être BERT de nom, mais pas de nature.
Pouvez-vous optimiser votre référencement pour BERT?
Probablement pas.
Le fonctionnement interne de BERT est complexe et multicouche. Tant et si bien, il y a même maintenant un domaine d'étude appelé « Bertologie » qui a été créé par l'équipe de Hugging Face.
Il est hautement improbable qu'un ingénieur de recherche interrogé puisse expliquer les raisons pour lesquelles quelque chose comme le BERT prendrait les décisions qu'il prend en ce qui concerne les classements (ou quoi que ce soit).
De plus, étant donné que le BERT peut être affiné sur plusieurs paramètres et plusieurs pondérations, puis s'auto-apprend de manière non supervisée, en boucle continue, il est considéré comme un algorithme à boîte noire. Une forme d'IA inexplicable.
On pense que le BERT ne sait pas toujours pourquoi il prend lui-même des décisions. Comment les SEO devraient-ils alors essayer de «l'optimiser» pour cela?
BERT est conçu pour comprendre le langage naturel, alors gardez-le naturel.
Nous devons continuer à créer des architectures de contenu et de sites Web convaincantes, engageantes, informatives et bien structurées de la même manière que vous écririez et construiriez des sites pour les humains.
Les améliorations sont du côté des moteurs de recherche et sont positives plutôt que négatives.
Google a simplement mieux compris la colle contextuelle fournie par la cohésion du texte dans les phrases et les phrases combinées et deviendra de mieux en mieux capable de comprendre les nuances à mesure que le BERT s'auto-apprend.
Les moteurs de recherche ont encore un long chemin à parcourir
Les moteurs de recherche ont encore un long chemin à parcourir et le BERT n'est qu'une partie de cette amélioration en cours de route, d'autant plus que le contexte d'un mot n'est pas le même que le contexte de l'utilisateur du moteur de recherche, ou les besoins d'information séquentiels qui sont des problèmes infiniment plus difficiles.
Les SEO ont encore beaucoup de travail à faire pour aider les utilisateurs des moteurs de recherche à trouver leur chemin et à répondre au bon besoin d'information au bon moment.