Que sont les "fraggles" en SEO et le lien avec mobile-first
 Cliquez sur l'image du tableau blanc ci-dessus pour ouvrir une version haute résolution dans un nouvel onglet!
Cliquez sur l'image du tableau blanc ci-dessus pour ouvrir une version haute résolution dans un nouvel onglet!
Transcription vidéo
Salut les fans de Moz. Je m'appelle Cindy Krum et je suis PDG de MobileMoxie , basée à Denver, Colorado. Nous faisons du SEO mobile et du conseil ASO. Je suis ici à Seattle, je parle à MozCon, mais j'enregistre également ce tableau blanc vendredi pour vous aujourd'hui, et nous parlons de fraggles.

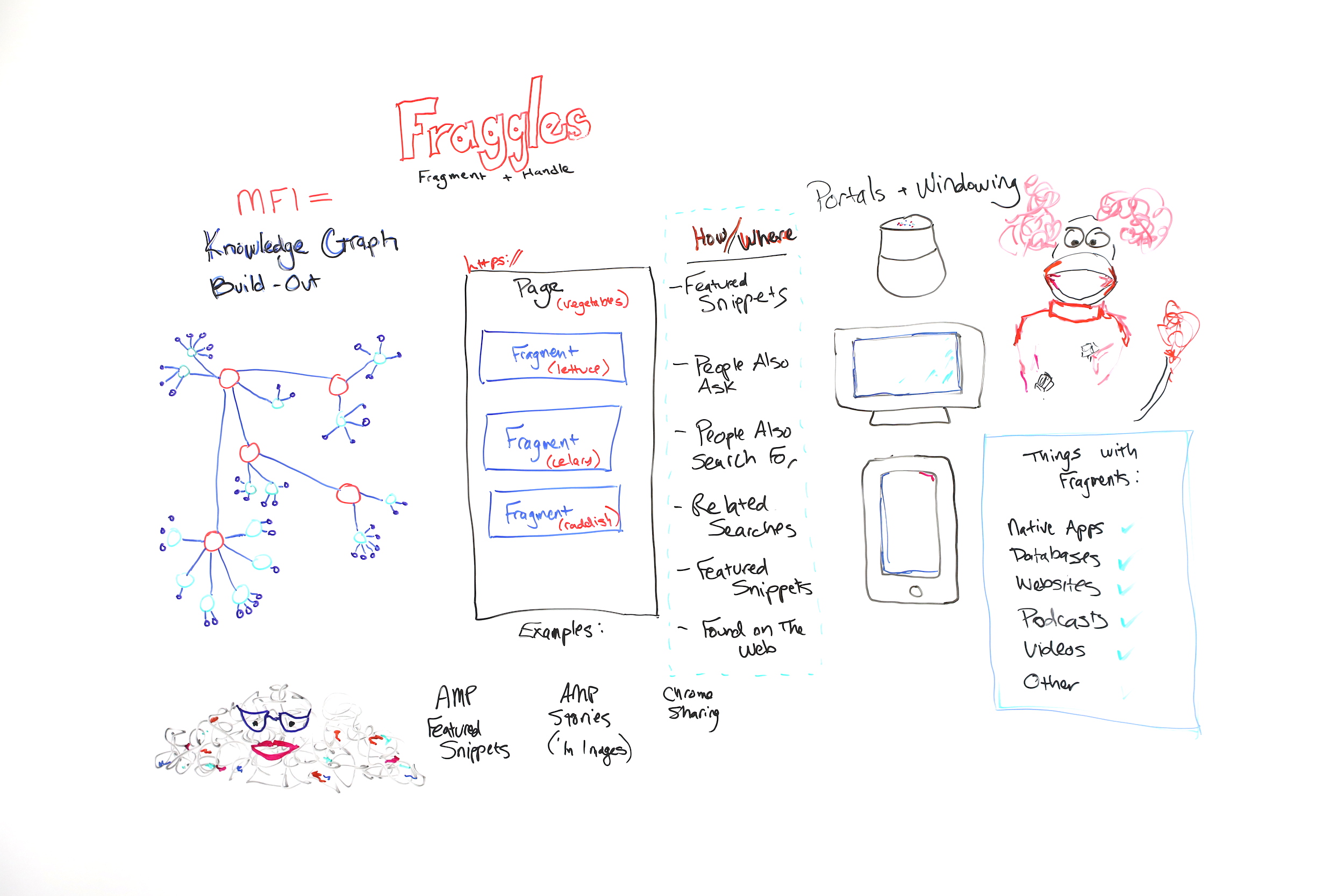
Donc, fraggles est évidemment un nom que j'emprunte à Jim Henson, qui a créé "Fraggle Rock". Mais c'est une combinaison de mots. C'est une combinaison de fragment et de poignée . Je parle de fraggles comme d'une nouvelle façon ou d'un nouvel élément ou chose que Google indexe.
Fraggles et indexation mobile-first
Commençons par l'idée de l'indexation mobile-first, car vous devez en quelque sorte comprendre cela avant de pouvoir comprendre les fraggles. Je pense donc que l'indexation mobile-first est un peu plus que ce que dit Google. Google dit que l'indexation mobile-first n'était qu'un changement du robot.
Ils avaient un robot de bureau qui explorait et indexait principalement, et maintenant ils ont un robot mobile qui fait le gros du travail pour l'exploration et l'indexation. Bien que je pense que c'est vrai, je pense qu'il y a plus de choses en coulisses dont ils ne parlent pas, et nous en avons vu beaucoup de preuves. Donc, ce que je crois, c'est que l'indexation mobile-first concernait également l'indexation, d'où le nom.
Graphique de connaissances et entités
Je pense donc que Google a réorganisé son index autour d'entités ou autour d' entités spécifiques dans le Knowledge Graph . C'est donc en quelque sorte mon schéma approximatif d'un graphe de connaissances très simplifié. Mais Knowledge Graph concerne la personne, le lieu, la chose ou l'idée.

Les noms sont des entités. Knowledge Graph a des nœuds pour toutes les principales personnes, lieux, choses ou entités d'idées. Mais il indexe aussi ou il organise aussi les relations de cette idée à cette idée ou de cette chose à cette chose. Ce qui est utile pour Google, c'est que ces choses, ces concepts, ces relations restent vrais dans toutes les langues, et c'est ainsi que les entités fonctionnent, car les entités se produisent avant les mots clés.
Cela peut être un concept difficile pour les SEO pour envelopper leur cerveau parce que nous sommes tellement habitués à traiter les mots clés. Mais si vous considérez une entité comme quelque chose qui est décrit par un mot-clé et peut être indépendant de la langue, c'est ainsi que Google pense les entités, car les entités dans le Knowledge Graph ne sont pas écrites en soi ou leur identifiant unique n'est pas un mot, c'est un nombre et les nombres sont indépendants de la langue.
Mais si nous pensons à une entité comme la mère , la mère est un concept qui existe dans toutes les langues, mais nous avons des mots différents pour le décrire. Mais quelle que soit la langue que vous parlez, la mère est liée au père, est liée à la fille, est liée au grand-père, toutes de la même manière, même si nous parlons des langues différentes. Donc, si Google peut utiliser ce qu'ils appellent la «couche thématique» et les entités comme un moyen de filtrer les informations et de comprendre le monde, alors ils peuvent le faire dans des langues où ils sont forts et dire: «Nous savons que cela est absolument vrai 100% tout le temps. "
Ensuite, ils peuvent appliquer cette compréhension aux langues qu'ils ont du mal à indexer ou à comprendre, ils ne sont tout simplement pas aussi forts ou l'algorithme n'est pas conçu pour comprendre des choses comme la complexité de la langue, comme l'allemand où ils font des mots très longs ou autres langues où ils ont beaucoup de mots courts pour signifier des choses différentes ou pour modifier des mots différents.
Les langues fonctionnent toutes différemment. Mais s'ils peuvent utiliser leur API de traduction et leurs API en langage naturel pour développer le graphe de connaissances dans les endroits où ils sont forts, ils peuvent l'utiliser avec l'apprentissage automatique pour le construire également et mieux répondre aux questions dans les endroits ou langues où ils sont faibles. Ainsi, lorsque vous comprenez cela, il est facile de penser à l'indexation mobile-first comme une construction massive de Knowledge Graph.
Nous avons vu cela se produire statistiquement. Il y a plus de résultats du graphe de connaissances et d'autres choses qui semblent être liées aux résultats du graphe de connaissances, comme les gens demandent aussi, les gens recherchent également, des recherches connexes. Ils décrivent tous différents éléments ou différents nœuds sur le graphe des connaissances. Donc, quand vous voyez ces choses dans la recherche, je veux que vous pensiez, hé, ceci est le graphe de connaissances me montrant comment ce sujet est lié à d'autres sujets.
Donc, lorsque Google a lancé l'indexation mobile d'abord, je pense que c'est la raison pour laquelle cela a pris deux ans et demi parce qu'ils réindexaient l'ensemble du Web et l'organisaient autour du Knowledge Graph. Si vous repensez à l'AMA que John Mueller a bien fait au moment du lancement de Knowledge Graph, il a répondu à de nombreuses questions concernant JavaScript et href lang.
Lorsque vous mettez cela dans ce contexte, cela a plus de sens. Il veut la compréhension de l'entité, ou il sait que la compréhension de l'entité est vraiment importante, donc le href lang est aussi vraiment important. Donc ça suffit. Parlons maintenant des fraggles.
Fraggles = fragment + poignée
Donc, comme je l'ai dit, les fraggles sont un fragment plus une poignée. Il est important de savoir que les fraggles - laissez-moi aller ici - les fraggles et les fragments, il y a beaucoup de choses qui ont des fragments. Vous pouvez donc penser aux applications natives, aux bases de données, aux sites Web, aux podcasts et aux vidéos. Tout cela peut être fragmenté.

Même s'ils n'ont pas d'URL, ils peuvent être un contenu utile, car Google dit que son objectif est d'organiser les informations du monde, pas d'organiser les sites Web du monde. Je pense que, historiquement, Google a été en quelque sorte enfermé dans l'exploration et l'indexation de sites Web et que cela le dérangeait, qu'il voulait pouvoir montrer d'autres choses, mais il ne pouvait pas le faire car ils avaient tous besoin d'URL.
Mais avec des fragments, ils n'ont potentiellement pas besoin d'avoir une URL. Gardez donc ces choses à l'esprit - les applications, les bases de données et des trucs comme ça - puis regardez ceci.

Il s'agit donc d'une page traditionnelle. Si vous pensez à une page, Google a en quelque sorte été contraint, historiquement par son infrastructure, de faire apparaître des pages et de classer des pages. Mais les pages ont parfois du mal à se classer si elles contiennent trop de sujets.
Ainsi, par exemple, ce que je vous ai montré ici est une page sur les légumes. Cette page peut être la meilleure page sur les légumes, et elle peut avoir les meilleures informations sur la laitue, le céleri et les radis. Mais parce qu'il y a ces sujets et peut-être plus de sujets dessus, ils se diluent tous en quelque sorte, et cette grande page peut avoir du mal à être classée parce qu'elle n'est pas concentrée sur un seul sujet, sur une chose à la fois.
Google veut classer les meilleures choses. Mais historiquement, ils nous ont en quelque sorte poussés à mettre les meilleures choses sur une page à la fois et à les faire ressortir. Donc, ce qui est créé, c'est cette mentalité "le contenu est roi, j'ai besoin de plus de contenu, de construire plus de pages" en SEO. Le problème est que tout le monde peut créer de plus en plus de pages pour chaque mot clé qu'il souhaite classer ou pour chaque groupe de mots clés qu'il souhaite classer, mais un seul va se classer numéro un.

Google doit encore explorer toutes les pages qu'il nous a dit de créer, et cela crée ce personnage ici, je pense, Marjory the Trash Heap, qui si vous vous souvenez des Fraggles, Marjory the Trash Heap était l'oracle omniscient. Mais lorsque nous créons tous des types de contenu de qualité faible à moyenne juste pour avoir une page séparée pour chaque sujet, cela rend la vie de Google plus difficile, et cela rend bien sûr notre vie plus difficile.
Alors pourquoi faisons-nous tout ce travail? La réponse est parce que Google ne peut indexer que des pages , et si la page est trop longue ou trop de sujets, Google est confus. Nous avons donc permis à Google de le faire. Mais faisons semblant, allez avec moi là-dessus, parce que c'est une théorie, je ne peux pas le prouver. Mais si Google n'a pas eu à indexer une page entière ou n'a pas été verrouillé dans cette page et pourrait simplement indexer un morceau de page, cela permet à Google de comprendre plus facilement les relations des différents sujets sur une seule page, mais aussi de organiser les bits de la page en différentes parties du graphe de connaissances.
Cette page sur les légumes pourrait donc être indexée et organisée sous le nœud végétal du Knowledge Graph. Mais cela ne signifie pas que la partie laitue de la page ne peut pas être indexée séparément sous la partie laitue du graphique de connaissances et ainsi de suite, céleri à céleri et radis à radis. Maintenant, je sais que c'est nouveau, et il est difficile de penser si vous faites du référencement depuis longtemps.
Mais réfléchissons aux raisons pour lesquelles Google voudrait faire cela. Google a évolué vers tous ces nouveaux types d'expériences de recherche où nous avons la recherche vocale, nous avons le genre de situation Google Home Hub avec un écran, ou nous avons des recherches mobiles. Si vous pensez à ce que Google a fait, nous avons également vu l'augmentation du nombre de personnes interrogées, et nous avons constaté l'augmentation des extraits de code en vedette.
En fait, ils ont en quelque sorte été, en quelque sorte en train de créer des fragments depuis longtemps ou d'indexer des fragments et de les montrer dans des extraits de journaux. La différence entre cela et fraggles est que lorsque vous cliquez sur un fraggle, lorsqu'il se classe dans un résultat de recherche, Google défile automatiquement vers cette partie de la page. C'est la partie poignée.
Des poignées dont vous avez peut-être déjà entendu parler. C'est une sorte de construction de sites Web à l'ancienne. Nous les appelons signets, liens d'ancrage, liens de saut d'ancrage, des trucs comme ça. C'est quand il défile automatiquement vers la partie droite de la page. Mais ce que nous avons vu avec fraggles, c'est que Google soulève des morceaux de texte, et lorsque vous cliquez dessus, ils défilent directement vers ce morceau de texte sur une page.
Nous constatons donc que cela se produit déjà dans certains résultats. Ce qui est intéressant, c'est que Google superpose le lien. Vous n'avez pas besoin de programmer le lien de saut là-dedans. Google le trouve réellement et le met là pour vous. Donc, Google le fait déjà, en particulier avec les extraits AMP. Si vous avez un extrait AMP en vedette, donc un extrait en vedette qui est extrait d'une page AMP, lorsque vous cliquez dessus, Google fait défiler et mettre en surbrillance l'extrait en vedette afin que vous puissiez le lire en contexte sur la page.
Mais cela se produit également dans d'autres types de situations plus nuancées, en particulier avec les forums et les conversations où ils peuvent choisir la meilleure réponse. La différence entre un fraggle et quelque chose comme un lien de saut est que Google superpose la partie de défilement. La différence entre un fraggle et un lien de site est un lien de liens de site vers d'autres pages, et fraggles, ils sont liés à plusieurs morceaux de la même longue page.
Donc , nous voulons éviter de continuer à construire des pages ou de faible qualité de qualité moyenne qui pourrait aller Marjory la Corbeille Heap. Nous voulons commencer à penser en termes de Google peut-il trouver et identifier la bonne partie de la page sur un sujet spécifique, et ces sujets sont-ils suffisamment liés pour être compris lors de leur indexation vers le Knowledge Graph.
Création d'un graphique des connaissances dans différents domaines
Je pense donc personnellement que nous assistons à la construction du Knowledge Graph dans beaucoup de choses différentes. Je pense que les extraits présentés sont des types de faits ou d'idées qui recherchent une maison ou une validation dans le graphique des connaissances. Les gens demandent également à être les nœuds liés. Les gens recherchent également la même chose. Recherches similaires, même chose. Extraits en vedette, oh, ils sont là deux fois, deux extraits en vedette. Trouvé sur le Web, qui est une autre façon où Google met les expandeurs par sujet et vous donne ensuite un carrousel d'extraits en vedette pour cliquer dessus.

Nous voyons donc toutes ces choses, et certains SEO sont en train de s'énerver que Google lève tellement de contenu et le place dans les résultats de recherche et que vous n'obtenez pas le clic. Nous savons que 61% des recherches sur mobile n'obtiennent plus de clic, et c'est parce que les gens trouvent les informations qu'ils souhaitent directement dans un SERP.
C'est difficile pour les SEO, mais génial pour Google car cela signifie que Google fournit exactement ce que l'utilisateur veut. Ils vont donc probablement continuer de le faire. Je pense que les SEO vont changer d'avis et ils voudront être dans ce contenu fenêtré, dans le contenu levé, parce que lorsque Google commence à faire ce genre de chose pour les applications natives, les bases de données et autres contenus, les sites Web , des podcasts, des trucs comme ça, alors ce sont de nouveaux concurrents avec lesquels vous n'avez pas eu à faire face quand il s'agissait uniquement de sites Web, mais ce seront des types de contenu plus attrayants que Google montrera ou lèvera et montrera dans un SERP même s'ils ne doivent pas avoir d'URL, car Google peut simplement les fenêtrer et les afficher.
Donc, vous préférez être levé que pas du tout montré. Voilà, c'est tout pour moi et des extraits en vedette. J'aimerais répondre à vos questions dans les commentaires et merci beaucoup. J'espère que vous aimez la théorie des fraggles.
Cindy Krum est la directrice générale de Rank-Mobile, LLC. Elle apporte des idées fraîches et créatives à ses clients, s'exprimant lors d'événements commerciaux nationaux et internationaux sur le marketing Web mobile, le marketing de réseau social et le référencement international. Cindy écrit également pour des publications de l'industrie et a été publiée dans Website Magazine, Advertising & Marketing Review, Search Engine Land, ODG Intelligence et citée par de nombreuses publications respectées, notamment PC World, Internet Retailer, TechWorld, Direct Magazine et Search Marketing Standard. Cindy est également coprésidente du groupe de travail sur le Web mobile SEMPO Emerging Technologies et est un membre actif de la communauté de recherche. Cindy est passionnée par la fourniture de solutions de marketing en ligne créatives aux clients,