Qu'est-ce que le Web Scraping et à quoi sert-il ?

Dans le monde concurrentiel d'aujourd'hui, tout le monde cherche des moyens d'innover et d'utiliser les nouvelles technologies. Le web scraping ( ou en francais le grattage Web, également appelé extraction de données Web ou grattage de données ) fournit une solution pour ceux qui souhaitent accéder à des données Web structurées de manière automatisée.
Le scraping Web est utile si le site Web public dont vous souhaitez obtenir des données n'a pas d'API, ou s'il en a, mais ne fournit qu'un accès limité aux données.
Dans cet article, nous allons faire la lumière sur le web scraping, voici ce que vous apprendrez :
Table des matières
Qu'est-ce que le web scraping?
Le web scraping est le processus de collecte de données Web structurées de manière automatisée. On l'appelle aussi extraction de données Web. Certains des principaux cas d'utilisation du web scraping incluent la surveillance des prix, la veille sur les prix, la surveillance des actualités, la génération de prospects et les études de marché, entre autres.
En général, l'extraction de données Web est utilisée par les personnes et les entreprises qui souhaitent utiliser la grande quantité de données Web accessibles au public pour prendre des décisions plus judicieuses.
Si vous avez déjà copié et collé des informations à partir d'un site Web, vous avez effectué la même fonction que n'importe quel grattoir Web, uniquement à une échelle manuelle microscopique. Contrairement au processus banal et abrutissant d'extraction manuelle de données, le web scraping utilise une automatisation intelligente pour récupérer des centaines, des millions, voire des milliards de points de données à partir de la frontière apparemment sans fin d'Internet.
Comment utiliser le web scraping ?
Que vous utilisiez vous-même un outil de grattage de données ou que vous sous-traitiez le travail à un spécialiste de l'extraction de données Web, vous aurez besoin d'en savoir un peu plus sur les différences entre l'exploration Web et web scraping. Tout aussi important, vous devrez comprendre les pièges possibles de l'extraction et comment les éviter. Lisez la suite pour découvrir comment fonctionne le web scraping et comment y parvenir avec succès.
Le web scraping est populaire
Et cela ne devrait pas être surprenant, car le web scraping fournit quelque chose de vraiment précieux que rien d'autre ne peut offrir : il vous fournit des données Web structurées à partir de n'importe quel site Web public.
Plus qu'une commodité moderne, la véritable puissance du web scraping réside dans sa capacité à créer et à alimenter certaines des applications commerciales les plus révolutionnaires au monde. Le terme « transformatif » ne décrit même pas la manière dont certaines entreprises utilisent les données extraites du Web pour améliorer leurs opérations, en informant les décisions des dirigeants jusqu'aux expériences de service client individuelles.
À quoi sert le web scraping ?
L'extraction de données Web, également connue sous le nom de grattage de données a une vaste gamme d'applications. Un outil de récupération de données peut vous aider à automatiser le processus d'extraction d'informations d'autres sites Web, rapidement et avec précision. Il peut également garantir que les données que vous avez extraites sont bien organisées et structurées, ce qui facilite leur analyse et leur utilisation pour d'autres projets.
Dans le monde du commerce électronique, le web scraping est largement utilisé pour surveiller les prix des concurrents. C'est le seul moyen pratique pour les marques de vérifier les prix des produits et services de leurs concurrents, leur permettant d'affiner leurs propres stratégies de prix et de garder une longueur d'avance. Il est également utilisé comme outil par les fabricants pour s'assurer que les détaillants se conforment aux directives de prix pour leurs produits. Les organismes d'études de marché et les analystes dépendent de l'extraction de données Web pour évaluer le sentiment des consommateurs en suivant les critiques de produits en ligne, les articles de presse et les commentaires.
Il existe une vaste gamme d'applications pour l'extraction de données dans le monde financier. Des outils de récupération de données sont utilisés pour extraire des informations à partir de reportages, en utilisant ces informations pour guider les stratégies d'investissement. De même, les chercheurs et les analystes dépendent de l'extraction de données pour évaluer la santé financière des entreprises. Les compagnies d'assurance et de services financiers peuvent exploiter une riche source de données alternatives extraites du Web pour concevoir de nouveaux produits et politiques pour leurs clients.
Les applications d'extraction de données Web ne s'arrêtent pas là. Les outils de web scraping sont largement utilisés dans la surveillance de l'actualité et de la réputation, le journalisme, la surveillance du référencement, l'analyse de la concurrence, le marketing basé sur les données et la génération de prospects, la gestion des risques, l'immobilier, la recherche universitaire et bien plus encore.
Les bases du web scraping
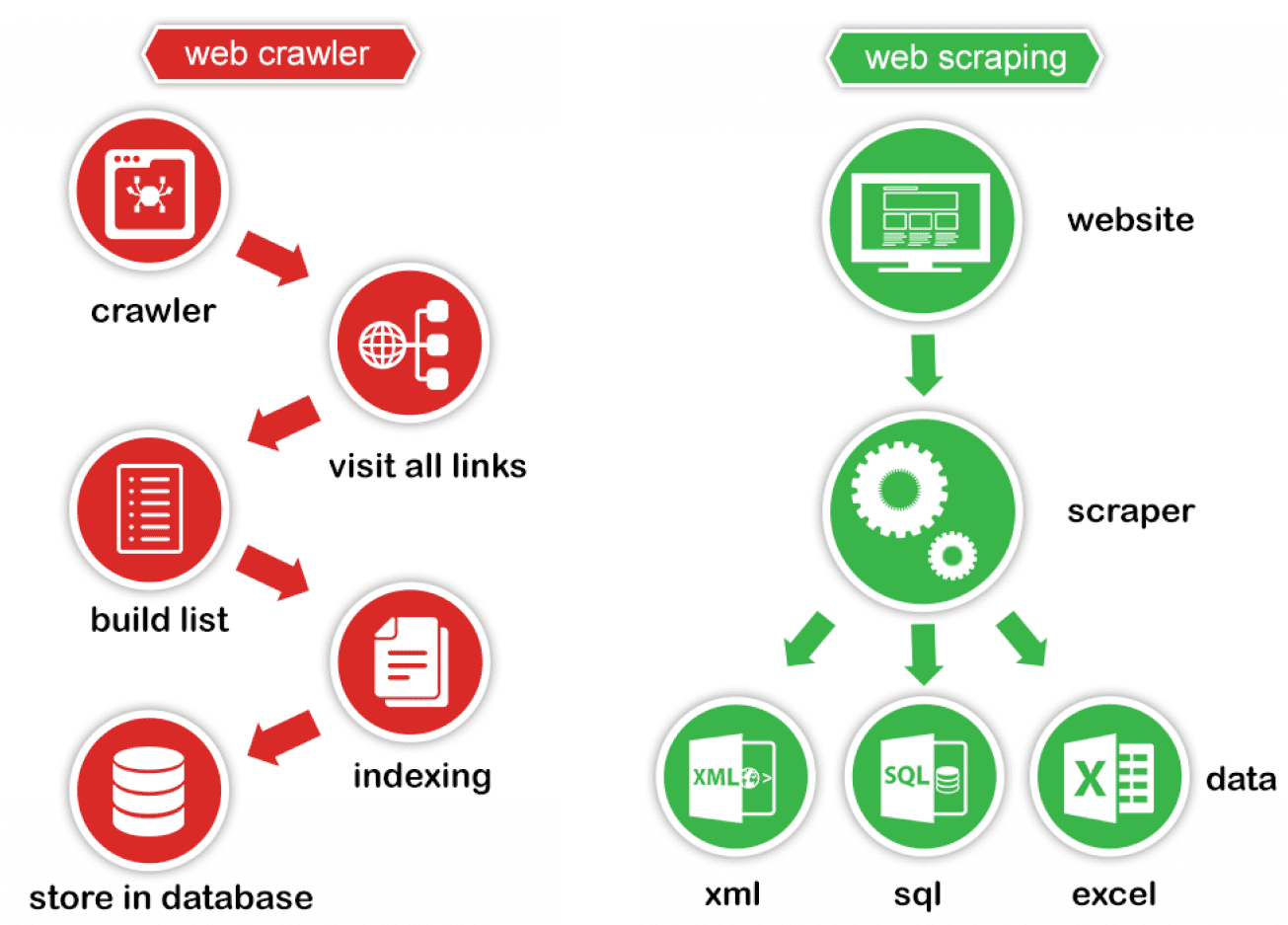
Image: sales-hacking.com
C'est extrêmement simple, en vérité, et fonctionne en deux parties : un robot d'indexation Web et un grattoir Web. Le robot d'indexation est le cheval et le grattoir est le char. Le crawler conduit le scraper, comme à la main, à travers Internet, où il extrait les données demandées. Découvrez la différence entre l'exploration Web et le web scraping et leur fonctionnement.
Le robot (The crawler)
Un robot d'exploration Web ou le crawler en anglais, que nous appelons généralement une « araignée » ou Spider en anglais, est une intelligence artificielle qui navigue sur Internet pour indexer et rechercher du contenu en suivant des liens et en explorant, comme une personne ayant trop de temps libre. Dans de nombreux projets, vous « explorez » d'abord le Web ou un site Web spécifique pour découvrir des URL que vous transmettez ensuite à votre grattoir.
Le grattoir (The scraper)
Un grattoir Web ou le scraper en anglais est un outil spécialisé conçu pour extraire avec précision et rapidité des données d'une page Web. Les grattoirs Web varient considérablement en termes de conception et de complexité, selon le projet. Une partie importante de chaque scraper est constituée des localisateurs de données (ou sélecteurs) qui sont utilisés pour trouver les données que vous souhaitez extraire du fichier HTML - généralement, XPath, sélecteurs CSS, regex ou une combinaison d'entre eux est appliqué.
Qu'est-ce qu'un outil de grattage (scraping tool?)
Un outil de grattage Web est un logiciel conçu spécifiquement pour extraire (ou « gratter ») des informations pertinentes à partir de sites Web. Vous utiliserez presque certainement une sorte d'outil de grattage chaque fois que vous collecterez des données à partir de pages Web par programmation.
Un outil de scraping effectue généralement des requêtes HTTP vers un site Web cible et extrait les données d'une page. Habituellement, il analyse le contenu accessible au public et visible par les utilisateurs et rendu par le serveur au format HTML. Parfois, il fait également des demandes aux interfaces de programmation d'applications (API) internes pour certaines données associées - comme les prix des produits ou les coordonnées - qui sont stockées dans une base de données et transmises à un navigateur via des requêtes HTTP.
Il existe différents types d'outils de grattage Web, avec des capacités qui peuvent être personnalisées pour s'adapter à différents projets d'extraction. Par exemple, vous pourriez avoir besoin d'un outil de grattage capable de reconnaître des structures de site HTML uniques, ou d'extraire, reformater et stocker des données à partir d'API.
Les outils de grattage peuvent être de grands cadres conçus pour toutes sortes de tâches de grattage typiques, mais vous pouvez également utiliser des bibliothèques de programmation à usage général et les combiner pour créer un grattoir.
Par exemple, vous pouvez utiliser une bibliothèque de requêtes HTTP - telle que la bibliothèque Python-Requests - et la combiner avec la bibliothèque Python BeautifulSoup pour extraire les données de votre page. Ou vous pouvez utiliser un framework dédié qui combine un client HTTP avec une bibliothèque d'analyse HTML. Un exemple populaire est Scrapy, une bibliothèque open source créée pour les besoins de grattage avancés.
Le processus de web scraping (grattage des données Web)
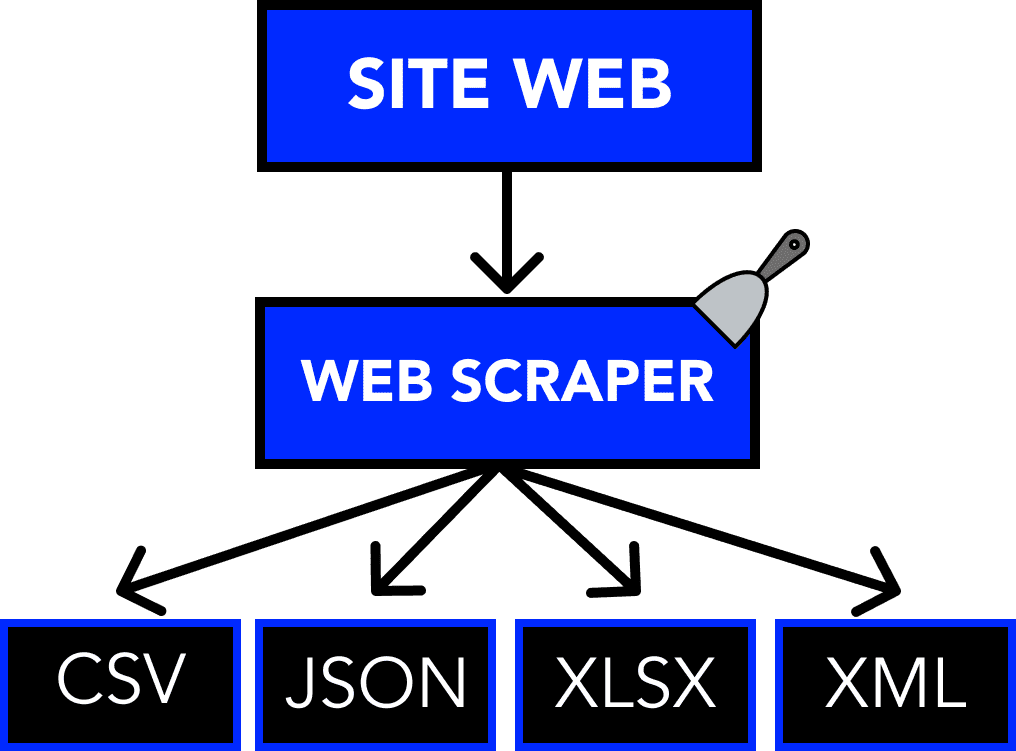
Image: sales-hacking.com
Si vous le faites vous-même à l'aide d'outils de grattage de sites Web
Voici à quoi ressemble un processus général de grattage Web DIY (data scraping process en anglais) :
-
Identifier le site cible
-
Collectez les URL des pages dont vous souhaitez extraire des données
-
Faire une demande à ces URL pour obtenir le HTML de la page
-
Utilisez des localisateurs pour trouver les données dans le HTML
-
Enregistrez les données dans un fichier JSON ou CSV ou dans un autre format structuré
Assez simple, non? Il l’est! Si vous avez juste un petit projet. Mais malheureusement, il y a pas mal de défis que vous devez relever si vous avez besoin de données à grande échelle. Par exemple, maintenir le scraper si la mise en page du site Web change, gérer les proxys, exécuter javascript ou contourner les antibots. Ce sont tous des problèmes profondément techniques qui peuvent consommer beaucoup de ressources. Il existe plusieurs outils de grattage de données Web open source que vous pouvez utiliser, mais ils ont tous leurs limites. C'est en partie pour cette raison que de nombreuses entreprises choisissent d'externaliser leurs projets de données Web.
Si vous l'externalisez
1. Une équipe recueille vos exigences concernant votre projet.
2. Une équipe chevronnée d'experts en grattage de données Web rédige le(s) grattoir(s) et met en place l'infrastructure pour collecter vos données et les structurer en fonction de vos besoins.
3. Enfin, nous livrons les données dans le format et la fréquence souhaités.
En fin de compte, la flexibilité et l'évolutivité du web scraping garantissent que les paramètres de votre projet, quelle que soit leur spécificité, peuvent être satisfaits facilement. Les détaillants de mode informent leurs créateurs des tendances à venir basées sur des informations extraites du Web, les investisseurs chronomètrent leurs stocks et les équipes marketing submergent la concurrence avec des informations approfondies, le tout grâce à l'adoption croissante du grattage Web en tant que partie intégrante des activités quotidiennes.
Que puis-je utiliser à la place d'un outil de web scraping?
Pour tous les projets, sauf les plus petits, vous aurez besoin d'une sorte d'outil de grattage Web automatisé ou de logiciel d'extraction de données pour obtenir des informations à partir de sites Web.
En théorie, vous pouvez couper et coller manuellement des informations de pages Web individuelles dans une feuille de calcul ou un autre document. Mais vous constaterez que cela est laborieux, long et sujet aux erreurs si vous essayez d'extraire des informations de centaines ou de milliers de pages.
Un outil de web scraping automatise le processus, en extrayant efficacement les données Web dont vous avez besoin et en les formatant dans une sorte de structure bien organisée pour le stockage et le traitement ultérieur.
Un autre moyen pourrait consister à acheter les données dont vous avez besoin auprès d'un fournisseur de services de données qui les extraira en votre nom. Cela serait utile pour les grands projets impliquant des dizaines de milliers de pages Web.
A quoi sert le web scraping ?
Renseignements sur les prix
D'après notre expérience, l'intelligence des prix est le cas d'utilisation le plus important pour le scraping Web. Extraire des informations sur les produits et les prix des sites Web de commerce électronique, puis les transformer en intelligence est une partie importante des entreprises de commerce électronique modernes qui souhaitent prendre de meilleures décisions de tarification/marketing basées sur des données.
Comment les données de tarification Web et les renseignements sur les prix peuvent être utiles :
-
Tarification dynamique
-
Optimisation des revenus
-
Veille concurrentielle
-
Suivi des tendances des produits
-
Conformité à la marque et au MAP
Étude de marché
Les études de marché sont essentielles et doivent être guidées par les informations les plus précises disponibles. Des données Web de haute qualité, volumineuses et très pertinentes, de toutes formes et de toutes tailles, alimentent l'analyse du marché et la veille économique à travers le monde.
-
Analyse des tendances du marché
-
Prix du marché
-
Optimisation du point d'entrée
-
Recherche & Développement
-
Veille concurrentielle
Données alternatives pour la finance
Découvrez l'alpha et créez radicalement de la valeur avec des données Web spécialement conçues pour les investisseurs. Le processus de prise de décision n'a jamais été aussi informé, ni les données aussi perspicaces - et les plus grandes entreprises du monde consomment de plus en plus de données extraites du Web, compte tenu de leur incroyable valeur stratégique.
-
Extraire des informations à partir des dépôts SEC
-
Estimation des fondamentaux de l'entreprise
-
Intégrations du sentiment public
-
Veille de l'actualité
Immobilier
La transformation numérique de l'immobilier au cours des vingt dernières années menace de perturber les entreprises traditionnelles et de créer de nouveaux acteurs puissants dans l'industrie. En incorporant des données de produits récupérées sur le Web dans leurs activités quotidiennes, les agents et les maisons de courtage peuvent se protéger contre la concurrence en ligne descendante et prendre des décisions éclairées sur le marché.
-
Évaluation de la valeur de la propriété
-
Suivi des taux de vacance
-
Estimation des rendements locatifs
-
Comprendre l'orientation du marché
Suivi des actualités et du contenu
Les médias modernes peuvent créer une valeur exceptionnelle ou une menace existentielle pour votre entreprise - en un seul cycle d'actualités. Si vous êtes une entreprise qui dépend d'analyses d'actualités en temps opportun, ou une entreprise qui apparaît fréquemment dans les actualités, le grattage des données d'actualités sur le Web est la solution ultime pour surveiller, agréger et analyser les histoires les plus critiques de votre secteur.
-
Prise de décision d'investissement
-
Analyse de l'opinion publique en ligne
-
Surveillance des concurrents
-
Campagnes politiques
-
Analyse des sentiments
Génération de leads
La génération de leads est une activité marketing/vente cruciale pour toutes les entreprises. Dans le rapport Hubspot 2020 , 61% des spécialistes du marketing entrant ont déclaré que la génération de trafic et de prospects était leur défi numéro 1. Heureusement, l'extraction de données Web peut être utilisée pour accéder à des listes de prospects structurées à partir du Web.
Veille de marque
Dans le marché hautement concurrentiel d'aujourd'hui, protéger votre réputation en ligne est une priorité absolue. Que vous vendiez vos produits en ligne et que vous ayez une politique de prix stricte que vous devez appliquer ou que vous vouliez simplement savoir comment les gens perçoivent vos produits en ligne, la surveillance de la marque avec le web scraping peut vous donner ce genre d'informations.
Automatisation des affaires
Dans certaines situations, il peut être difficile d'accéder à vos données. Peut-être avez-vous besoin d'extraire des données d'un site Web qui est le vôtre ou celui de votre partenaire de manière structurée. Mais il n'y a pas de moyen interne simple de le faire et il est logique de créer un grattoir et de simplement récupérer ces données. Au lieu d'essayer de vous frayer un chemin à travers des systèmes internes compliqués.
Surveillance de la MAP
La surveillance du prix minimum annoncé (MAP) est la pratique standard pour s'assurer que les prix en ligne d'une marque sont alignés sur sa politique de prix. Avec des tonnes de revendeurs et de distributeurs, il est impossible de surveiller les prix manuellement. C'est pourquoi le web scraping est pratique car vous pouvez garder un œil sur les prix de vos produits sans lever le petit doigt.
Comment puis-je extraire gratuitement des données d'un site Web ?
Il existe diverses solutions de grattage gratuites disponibles qui vous permettent d'automatiser le processus d'extraction de données à partir du Web. Celles-ci vont des simples solutions de grattage pointer-cliquer destinées aux non-spécialistes à des applications plus puissantes axées sur les développeurs avec des options de configuration et de gestion étendues.
Si vous consultez un site Web, comme vous le faites maintenant, vous pouvez simplement copier et coller les informations que vous lisez à l'écran dans un autre document, comme une feuille de calcul. C'est certainement une façon d'extraire des données Web gratuitement. Mais la collecte manuelle d'informations de cette manière va être lente, inefficace et sujette aux erreurs pour toutes les tâches, sauf les plus simples.
En pratique, vous chercherez des moyens d'automatiser le processus de web scraping, vous permettant d'extraire des données de nombreuses pages Web – peut-être des milliers ou des millions d'entre elles par jour – et d'organiser les résultats dans une structure bien organisée. Pour y parvenir, vous aurez besoin d'une sorte d'outil d'extraction de données Web, souvent appelé grattoir Web ou scraping tool.
Il existe de nombreuses solutions de grattage gratuites pour extraire des données du Web. Certaines d'entre elles sont des applications dédiées destinées aux programmeurs, nécessitant un niveau de compétence en codage pour configurer et gérer.
Idéal pour les non-spécialistes ayant des besoins d'extraction modérés, il existe également des grattoirs faciles à utiliser qui s'exécutent comme une extension de navigateur ou un plug-in avec une simple interface pointer-cliquer. Moins sophistiqués que leurs homologues axés sur les développeurs, ils sont généralement plus limités dans la variété et le volume de données qu'ils vous permettent de récupérer.