Chapitre 2: Fonctionnement des moteurs de recherche: exploration, indexation et classement
Comme nous l'avons mentionné au CHAPITRE 1: QU'EST-CE QUE C'EST LE RÉFÉRENCEMENT (SEO) ET POURQUOI EST-CE IMPORTANT? , les moteurs de recherche sont des répondeurs. Ils existent pour découvrir, comprendre et organiser le contenu d'Internet afin d'offrir les résultats les plus pertinents aux questions des chercheurs.
Pour apparaître dans les résultats de recherche, votre contenu doit d'abord être visible pour les moteurs de recherche. C'est sans doute la pièce la plus importante du puzzle SEO: si votre site ne peut pas être trouvé, il n'y a aucun moyen que vous vous présentiez dans la SERP (Search Engine Results Page).
Contenu
- Comment fonctionnent les moteurs de recherche?.
- Qu'est-ce que l'exploration des moteurs de recherche?.
- Qu'est-ce qu'un index de moteur de recherche?.
- Classement des moteurs de recherche.
- En SEO, tous les moteurs de recherche ne sont pas égaux.
- Exploration: les moteurs de recherche peuvent-ils trouver vos pages?.
- Expliquez aux moteurs de recherche comment explorer votre site.
- Les robots d'exploration peuvent-ils trouver tout votre contenu important?.
- Avez-vous une architecture d'information propre?.
- Utilisez-vous des plans de site (Sitemaps)?.
- Les robots d'exploration reçoivent-ils des erreurs lorsqu'ils tentent d'accéder à vos URL?.
- Créez des pages 404 personnalisées!
- Attention aux chaînes de redirection!
- Indexation: comment les moteurs de recherche interprètent-ils et stockent-ils vos pages?.
- Puis-je voir comment un robot d'exploration Googlebot voit mes pages?.
- Les pages sont-elles jamais supprimées de l'index?.
- Dites aux moteurs de recherche comment indexer votre site.
- Méta-directives robots.
- Les directives méta affectent l'indexation, pas l'analyse.
- Classement: comment les moteurs de recherche classent-ils les URL?.
- Mesures d'engagement: corrélation, causalité ou les deux?.
- L'évolution des résultats de recherche.
Comment fonctionnent les moteurs de recherche?
Les moteurs de recherche ont trois fonctions principales: explorer, indexer et classer.
Les moteurs de recherche ont pour fonction principale de permettre aux utilisateurs d'Internet de trouver rapidement et facilement des informations pertinentes en explorant le contenu disponible sur le web. Pour ce faire, ils suivent un processus en trois étapes : exploration, indexation et classement.
Tout d'abord, les moteurs de recherche explorent le web pour trouver du contenu, en suivant des liens d'une page à l'autre pour découvrir de nouvelles informations. Ils examinent le code et le contenu de chaque URL qu'ils trouvent pour déterminer leur pertinence et leur importance.
Une fois qu'ils ont trouvé du contenu pertinent, les moteurs de recherche l'indexent, c'est-à-dire qu'ils le stockent et l'organisent de manière à pouvoir le retrouver facilement. Les pages web sont ajoutées à des bases de données, où elles peuvent être consultées par les moteurs de recherche lorsqu'un utilisateur effectue une recherche.
Enfin, les moteurs de recherche classent les résultats de recherche pour répondre au mieux aux requêtes des utilisateurs. Ils utilisent des algorithmes complexes pour évaluer la pertinence de chaque page indexée et la classer en fonction de différents critères tels que la qualité du contenu, la pertinence des mots-clés et l'autorité de la page. Les résultats les plus pertinents apparaissent en haut de la page de résultats, tandis que les moins pertinents se trouvent en bas.
Par exemple, si vous recherchez "recette de brownies" sur un moteur de recherche, il explorera le web pour trouver des pages contenant des recettes de brownies. Il les indexera et les classera en fonction de leur pertinence pour répondre à votre requête, en affichant les résultats les plus pertinents en haut de la page de résultats.
Qu'est-ce que l'exploration des moteurs de recherche?
L'exploration est une étape essentielle du fonctionnement des moteurs de recherche. Elle consiste en l'envoi d'engins (ou robots) pour parcourir l'ensemble d'Internet en suivant des liens pour découvrir du contenu nouveau et/ou mis à jour. Les moteurs de recherche utilisent ces engins, tels que Googlebot, pour analyser le code et le contenu des pages Web afin de déterminer leur pertinence pour les utilisateurs effectuant des recherches en ligne.
Les robots d'exploration suivent des liens à partir de pages Web déjà indexées et continuent à parcourir le Web en suivant les liens des nouvelles pages qu'ils découvrent, créant ainsi une sorte de toile d'araignée qui couvre la plupart des pages du Web. C'est pourquoi il est important d'avoir des liens internes sur votre site Web pour aider les robots à explorer et à indexer votre contenu plus efficacement.
L'exploration est également importante pour maintenir l'index des moteurs de recherche à jour en ajoutant de nouveaux contenus et en supprimant ceux qui ne sont plus pertinents. Les robots d'exploration peuvent également détecter les erreurs techniques sur les pages Web telles que les pages d'erreur 404 ou les liens cassés.
En bref, l'exploration est le processus de découverte de nouveaux contenus sur Internet et c'est une étape essentielle du fonctionnement des moteurs de recherche. Les robots d'exploration sont utilisés pour découvrir, analyser et indexer les pages Web en suivant les liens à partir de pages déjà indexées.
Qu'est-ce qu'un index de moteur de recherche?
L'index de moteur de recherche peut être considéré comme une gigantesque bibliothèque de l'ensemble des pages web explorées et analysées par les robots d'exploration des moteurs de recherche. Il est important de noter que tous les moteurs de recherche n'indexent pas les mêmes pages, car ils ont chacun leur propre algorithme et leurs propres critères de sélection pour déterminer les pages qui méritent d'être indexées.
Le contenu extrait lors de l'exploration est ensuite stocké dans l'index, qui peut être comparé à un annuaire inversé. Au lieu de trier les pages par ordre alphabétique, l'index trie les pages par mot-clé. Par exemple, si un utilisateur recherche "chien", l'index renverra une liste de pages contenant le mot-clé "chien".
Les moteurs de recherche utilisent ensuite leurs algorithmes pour classer les pages de l'index en fonction de leur pertinence, de leur qualité, de leur autorité et de leur pertinence pour la requête de l'utilisateur. Ces algorithmes utilisent un large éventail de facteurs, tels que la qualité du contenu, la pertinence des mots-clés, l'autorité de la page, la pertinence géographique et bien plus encore.
Il est important de noter que l'indexation est un processus continu, car les moteurs de recherche découvrent constamment de nouveaux contenus sur le web. De plus, les pages existantes sont régulièrement mises à jour, de sorte que les robots d'exploration doivent continuellement réindexer ces pages pour s'assurer que les résultats de recherche restent pertinents et à jour.
En résumé, l'index de moteur de recherche est un outil essentiel qui permet aux utilisateurs de trouver rapidement des informations pertinentes sur le web en reliant les mots-clés de leur requête à des pages web contenant ces mots-clés dans l'index. Les moteurs de recherche utilisent ensuite leur algorithme pour classer et organiser les pages stockées dans l'index, en fonction de facteurs tels que la pertinence, la qualité, l'autorité et la pertinence.
Classement des moteurs de recherche
Lorsque quelqu'un effectue une recherche, les moteurs de recherche parcourent leur index pour trouver du contenu très pertinent, puis affichent ce contenu dans l'espoir de résoudre la requête du chercheur. Cet ordre des résultats de recherche par pertinence est appelé classement. En général, vous pouvez supposer que plus un site Web est classé, plus le moteur de recherche estime que ce site est pertinent pour la requête.
Il est possible de bloquer les robots d'exploration des moteurs de recherche d'une partie ou de la totalité de votre site, ou de demander aux moteurs de recherche d'éviter de stocker certaines pages dans leur index. Bien qu'il puisse y avoir des raisons de le faire, si vous souhaitez que votre contenu soit trouvé par les chercheurs, vous devez d'abord vous assurer qu'il est accessible aux robots d'exploration et qu'il est indexable.
À la fin de ce chapitre, vous aurez le contexte dont vous avez besoin pour travailler avec le moteur de recherche, plutôt que contre lui!
En SEO, tous les moteurs de recherche ne sont pas égaux
De nombreux débutants s'interrogent sur l'importance relative de certains moteurs de recherche. La plupart des gens savent que Google détient la plus grande part de marché, mais dans quelle mesure est-il important d'optimiser pour Bing, Yahoo et autres? La vérité est que, malgré l'existence de plus de 30 principaux moteurs de recherche Web, la communauté SEO ne fait vraiment attention qu'à Google. Pourquoi? La réponse courte est que Google est l'endroit où la grande majorité des gens effectuent leurs recherches sur le Web. Si nous incluons Google Images, Google Maps et YouTube (une propriété Google), plus de 90% des recherches sur le Web ont lieu sur Google, soit près de 20 fois Bing et Yahoo combinés.
Voici plus de détails sur la part de marché des principaux moteurs de recherche :
- Google : Selon Statcounter, Google détient une part de marché mondiale d'environ 91,8% des recherches effectuées sur ordinateur en 2023. Sur mobile, cette part de marché est d'environ 93,6%.
- Bing : Bing détient la deuxième plus grande part de marché, avec environ 2,6% des recherches sur ordinateur et 1,2% des recherches sur mobile en 2023.
- Yahoo : Yahoo est en troisième position, avec une part de marché d'environ 1,2% sur ordinateur et 1,1% sur mobile en 2023.
- Baidu : En Chine, Baidu reste le moteur de recherche dominant en 2023, avec une part de marché d'environ 73% selon Statcounter.
- Yandex : En Russie, Yandex est toujours le moteur de recherche le plus utilisé en 2023, avec une part de marché d'environ 58%.
Il est important de noter que les parts de marché peuvent varier selon les pays et les régions. Toutefois, dans l'ensemble, Google est de loin le moteur de recherche le plus important pour la plupart des sites Web, car il est utilisé pour plus de 90% des recherches effectuées sur le Web dans le monde entier.
Exploration: les moteurs de recherche peuvent-ils trouver vos pages?
Comme vous venez de l'apprendre, vous assurer que votre site est analysé et indexé est une condition préalable pour apparaître dans les SERPs. Si vous avez déjà un site Web, il est peut-être judicieux de commencer par voir le nombre de vos pages dans l'index. Cela vous permettra de savoir si Google explore et trouve toutes les pages de votre site web.
Une façon de vérifier vos pages indexées est de tapez la commande suivante dans la barre de recherche "site: votredomaine.com. Cela renverra les résultats que Google a dans son index pour le site spécifié:
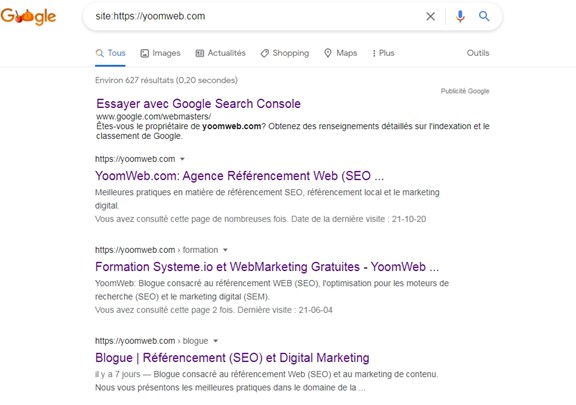
Le nombre de résultats affichés par Google (voir « Environ XX résultats » ci-dessus) n'est pas exact, mais il vous donne une idée précise des pages indexées sur votre site et de la façon dont elles apparaissent actuellement dans les résultats de recherche.
Pour des résultats plus précis, surveillez et utilisez le rapport de couverture d'index dans Google Search Console. Vous pouvez vous inscrire gratuitement si vous n'avez pas encore de compte. Avec cet outil, vous pouvez, entre autres, soumettre des sitemaps (Plans de site) pour votre site et surveiller le nombre de pages soumises qui ont été réellement ajoutées à l'index de Google.
Si vous n'apparaissez nulle part dans les résultats de recherche, il y a plusieurs raisons possibles:
- Votre site est flambant neuf et n'a pas encore été exploré.
- Votre site n'est lié à aucun site Web externe.
- La navigation de votre site rend difficile pour un robot de l'explorer efficacement.
- Votre site contient du code qui bloque les moteurs de recherche.
- Votre site a été pénalisé par Google pour ses tactiques de spam ou autres.
Expliquez aux moteurs de recherche comment explorer votre site
Si vous avez utilisé Google Search Console ou l'opérateur de recherche avancé « site: domaine.com » et avez constaté que certaines de vos pages importantes manquaient dans l'index et / ou que certaines de vos pages sans importance avaient été indexées par erreur, vous pouvez opter pour certaines optimisations pour mieux diriger Googlebot a mieux exploité votre contenu. Dire aux moteurs de recherche comment explorer votre site peut vous donner un meilleur contrôle de ce qui se retrouve dans l'index.
La plupart des gens pensent à s'assurer que Google puisse trouver leurs pages importantes, mais il est facile d'oublier qu'il y a probablement des pages que vous ne souhaitez pas que Googlebot trouve. Il peut s'agir, par exemple, d'anciennes URL à contenu léger, d'URL en double (telles que les paramètres de tri et de filtrage pour le commerce électronique), de pages de codes promotionnels spéciales, de pages de test, etc.
Pour interdire Googlebot à explorer et indexer certaines pages et sections de votre site, utilisez le fichier robots.txt qui se retrouve à la racine de votre site web.
Le fichier Robots.txt
Le fichier robots.txt est un fichier texte situé à la racine d'un site Web qui indique aux robots d'exploration des moteurs de recherche les pages du site qu'ils sont autorisés à explorer ou non. Les directives incluses dans ce fichier peuvent également spécifier la fréquence à laquelle les robots doivent explorer le site et s'ils doivent suivre ou non les liens présents sur les pages.
Cependant, il est important de noter que les robots d'exploration ne sont pas obligés de respecter les directives du fichier robots.txt, il s'agit plutôt d'une recommandation. En outre, les pages non incluses dans le fichier robots.txt peuvent toujours être découvertes et indexées par les moteurs de recherche, par exemple si des liens externes pointent vers ces pages.
Le fichier robots.txt est donc un outil utile pour gérer la manière dont les robots d'exploration accèdent à votre site Web, mais il ne garantit pas une exclusion totale de certaines parties de votre site.
Comment Googlebot traite les fichiers robots.txt
Googlebot est le robot de recherche de Google qui parcourt le Web pour indexer les pages pour les résultats de recherche. Lorsque Googlebot visite un site, il vérifie d'abord s'il y a un fichier robots.txt. Ce fichier est un fichier texte qui indique aux robots des moteurs de recherche quoi indexer et quoi ne pas indexer sur votre site.
Si un fichier robots.txt est présent sur le site, Googlebot le respectera et n'indexera pas les pages qui y sont interdites. Si le fichier robots.txt n'est pas présent ou s'il ne contient pas d'instructions pour Googlebot, ce dernier indexera normalement le site.
Il est important de noter que le fichier robots.txt ne sert qu'à donner des instructions aux robots des moteurs de recherche et ne garantit pas qu'ils les suivront. Il existe des outils en ligne qui permettent aux utilisateurs de voir les fichiers robots.txt des sites, ce qui peut rendre les pages interdites visibles pour les utilisateurs malveillants. Par conséquent, il est important de ne pas utiliser le fichier robots.txt pour masquer des informations sensibles ou protégées.
Optimisez pour le budget d'exploration!
Le budget d'exploration est le nombre moyen d'URL que Googlebot explorera sur votre site avant de quitter, donc l'optimisation du budget d'exploration garantit que Googlebot ne perd pas de temps à parcourir vos pages sans importance au risque d'ignorer vos pages importantes.
Le budget d'exploration est le plus important sur les très grands sites avec des dizaines de milliers d'URL , mais ce n'est jamais une mauvaise idée d'empêcher les robots d'exploration d'accéder au contenu qui ne vous intéresse vraiment pas.
Assurez-vous simplement de ne pas bloquer l'accès d'un robot aux pages sur lesquelles vous avez ajouté d'autres directives, telles que des balises canoniques ou noindex. Si Googlebot est bloqué sur une page, il ne pourra pas voir les instructions sur cette page.
Tous les robots Web ne suivent pas robots.txt. Les personnes mal intentionnées (par exemple, les grattoirs d'adresse e-mail) créent des bots qui ne suivent pas ce protocole. En fait, certains mauvais acteurs utilisent des fichiers robots.txt pour trouver où vous avez localisé votre contenu privé. Bien qu'il puisse sembler logique de bloquer les robots d'exploration des pages privées telles que les pages de connexion et d'administration afin qu'elles n'apparaissent pas dans l'index, le fait de placer l'emplacement de ces URL dans un fichier robots.txt accessible au public signifie également que les personnes ayant une intention malveillante peut plus facilement les trouver. Il vaut mieux d’utiliser la balise NoIndex pour ces pages et les placer derrière un formulaire de connexion plutôt que de les placer dans votre fichier robots.txt.
Définition des paramètres d'URL dans le Google Search Console (GSC)
Certains sites (les plus courants avec le commerce électronique et les CMS comme Wordpress et Joomla) rendent le même contenu disponible sur plusieurs URL différentes en ajoutant certains paramètres aux URL. Si vous avez déjà fait des achats en ligne, vous avez probablement restreint votre recherche via des filtres. Par exemple, vous pouvez rechercher des « eBooks » sur Amazon, puis affiner votre recherche par taille, couleur et style. Chaque fois que vous affinez, l'URL change légèrement, mais c’est le même contenu.
Comment Google fait-il pour savoir quelle version de l'URL doit être diffusée aux internautes? Google fait un très bon travail pour déterminer l'URL représentative de son propre chef, mais vous pouvez utiliser la fonctionnalité Paramètres d'URL dans Google Search Console pour indiquer à Google exactement comment vous souhaitez qu'ils traitent vos pages. Si vous utilisez cette fonctionnalité pour indiquer à Googlebot «ne pas explorer d'URL avec le paramètre », vous demandez essentiellement de masquer ce contenu à Googlebot, ce qui pourrait entraîner la suppression de ces pages des résultats de recherche. C'est ce que vous voulez si ces paramètres créent des pages en double, mais pas idéal si vous voulez que ces pages soient indexées. Il faut utiliser cette fonctionnalité avec prudence. En général, Google fait un bon travail pour vous sans l’utiliser. D’ailleurs cette fonctionnalité est rendue désuète et très rarement utilisée par les experts.
Les robots d'exploration peuvent-ils trouver tout votre contenu important?
Maintenant que vous connaissez certaines tactiques pour garantir que les robots des moteurs de recherche restent à l'écart de votre contenu sans importance, voyons les optimisations qui peuvent aider Googlebot à trouver vos pages importantes.
Parfois, un moteur de recherche pourra trouver des parties de votre site en rampant, mais d'autres pages ou sections peuvent être obscurcies pour une raison ou une autre. Il est important de s'assurer que les moteurs de recherche sont en mesure de découvrir tout le contenu que vous souhaitez indexer, et pas seulement votre page d'accueil.
Voici quelques optimisations pour aider Googlebot à trouver vos pages importantes :
1. Utilisez un sitemap XML (ou RSS): un sitemap XML est un fichier qui répertorie toutes les pages importantes de votre site Web et indique aux moteurs de recherche où les trouver.
2. Utilisez des liens internes : assurez-vous que vos pages sont liées entre elles afin que les moteurs de recherche puissent suivre les liens pour trouver les pages importantes.
3. Évitez les liens cassés : les liens cassés peuvent empêcher les moteurs de recherche de trouver des pages importantes. Assurez-vous que tous les liens sur votre site sont valides.
4. Utilisez des balises title et meta description : ces balises aident les moteurs de recherche à comprendre le contenu de vos pages.
5. Créez un contenu de qualité : des pages avec un contenu utile et informatif ont plus de chances d'être trouvées et indexées par les moteurs de recherche.
6. Utilisez des URL conviviales : les URL conviviales sont plus faciles à comprendre pour les moteurs de recherche et peuvent aider à améliorer le référencement de votre site.
En suivant ces optimisations, vous pouvez aider les moteurs de recherche à découvrir et à indexer toutes les pages importantes de votre site Web.
Votre contenu est-il caché derrière les formulaires de connexion?
Si vous demandez aux utilisateurs de se connecter, de remplir des formulaires ou de répondre à des sondages avant d'accéder à certains contenus, les moteurs de recherche ne verront pas ces pages protégées. Un robot ne va certainement pas se connecter.
Les moteurs de recherche ne pourront pas accéder au contenu protégé par des formulaires de connexion ou d'inscription, car les robots ne peuvent pas remplir ces champs comme le feraient les utilisateurs. Pour cette raison, il est important de s'assurer que le contenu que vous souhaitez indexer est accessible aux robots des moteurs de recherche en évitant de placer des barrières telles que des formulaires de connexion ou d'inscription. Si vous devez absolument protéger certains contenus, vous pouvez envisager de les mettre en évidence sur une autre page accessible aux moteurs de recherche et d'y inclure des liens pour inciter les utilisateurs à se connecter ou à s'inscrire pour y accéder.
Comptez-vous sur des formulaires de recherche?
Les robots ne peuvent pas utiliser les formulaires de recherche. Certaines personnes pensent que si elles placent un champ de recherche sur leur site, les moteurs de recherche pourront trouver tout ce que leurs visiteurs recherchent.
Le texte est-il caché dans le contenu non textuel?
Les formulaires multimédias non textuels (images, vidéo, GIF, etc.) ne doivent pas être utilisés pour afficher le texte que vous souhaitez indexer. Bien que les moteurs de recherche améliorent la reconnaissance des images, rien ne garantit qu'ils seront en mesure de les lire et de les comprendre tout de suite. Il est toujours préférable d'ajouter du texte dans le balisage <HTML> de votre page Web.
Les moteurs de recherche peuvent-ils suivre la navigation de votre site?
Tout comme un robot a besoin de découvrir votre site via des liens provenant d'autres sites, il a besoin d'un chemin de liens sur votre propre site pour le guider de page en page. Si vous avez une page que vous souhaitez que les moteurs de recherche trouvent mais qui n'est liée à aucune autre page de votre site, elle est aussi invisible.
De nombreux sites commettent l'erreur critique de structurer leur navigation de manière inaccessible aux moteurs de recherche, ce qui entrave leur capacité à figurer dans les résultats de recherche.
Erreurs de navigation courantes qui peuvent empêcher les robots d'exploration de voir l'intégralité de votre site:
Voici quelques erreurs de navigation courantes qui peuvent empêcher les robots d'exploration de voir l'intégralité de votre site :
- Mauvaise configuration de robots.txt : Le fichier robots.txt est utilisé pour donner des instructions aux robots d'exploration sur les parties du site qu'ils sont autorisés à explorer ou non. Si ce fichier est mal configuré, il peut empêcher les robots d'explorer certaines parties du site.
- Liens brisés : Les liens brisés sont des liens qui ne fonctionnent pas et qui peuvent empêcher les robots d'exploration d'atteindre certaines parties du site. Il est important de vérifier régulièrement les liens pour s'assurer qu'ils sont tous valides.
- Pages non indexables : Certains types de pages, tels que les pages de connexion ou les pages de confirmation de commande, ne devraient pas être indexés par les moteurs de recherche. Si ces pages sont indexées, cela peut diluer la qualité de l'index du moteur de recherche et rendre plus difficile pour les utilisateurs de trouver les pages pertinentes.
- Contenu bloqué par JavaScript : Les robots d'exploration ont du mal à interpréter le contenu bloqué par JavaScript. Si une grande partie du contenu de votre site est bloquée par JavaScript, les robots d'exploration peuvent ne pas être en mesure d'explorer toutes les parties du site.
- Pages trop profondes : Si les pages de votre site sont trop profondes (c'est-à-dire qu'elles sont situées à plusieurs niveaux de profondeur dans la hiérarchie du site), cela peut rendre difficile pour les robots d'exploration de les trouver.
- Erreurs de redirection : Les erreurs de redirection, telles que les erreurs 301 et 302, peuvent empêcher les robots d'exploration d'atteindre certaines parties du site. Il est important de s'assurer que toutes les redirections sont correctement configurées.
Il est important de s'assurer que toutes les parties du site sont accessibles aux robots d'exploration en évitant les erreurs de navigation courantes mentionnées ci-dessus.
Avez-vous une architecture d'information propre?
Une architecture d'information propre, claire et intuitive est essentielle pour que les utilisateurs puissent facilement trouver ce qu'ils cherchent sur votre site Web. Cela peut aider à améliorer l'expérience utilisateur, à augmenter le taux de conversion et à encourager les utilisateurs à revenir sur votre site Web à l'avenir.
Une bonne architecture de l'information peut également aider les moteurs de recherche à comprendre la structure de votre site Web et à classer vos pages de manière appropriée. Il est donc important de planifier soigneusement la structure de votre site Web avant de le construire, en veillant à ce que l'information soit organisée de manière cohérente et logique.
Voici quelques éléments clés à prendre en compte pour créer une architecture d'information propre, claire et intuitive :
- Organisation logique : organisez le contenu de manière à ce que les utilisateurs puissent facilement comprendre la structure et la hiérarchie des informations présentées. Cela peut être fait en utilisant des catégories, des sous-catégories et des étiquettes claires.
- Navigation claire : assurez-vous que les utilisateurs peuvent naviguer facilement sur votre site, en utilisant une navigation claire et cohérente. Cela peut être réalisé en utilisant des menus déroulants, des liens de navigation dans le pied de page, des barres latérales et des liens internes dans le contenu.
- Conception adaptative : veillez à ce que votre site soit facile à utiliser sur tous les appareils, y compris les téléphones mobiles et les tablettes. Cela signifie que votre site doit être conçu de manière responsive, c'est-à-dire qu'il doit s'adapter automatiquement à la taille de l'écran de l'appareil utilisé.
- Étiquetage clair : assurez-vous que chaque page de votre site est correctement étiquetée avec des titres et des descriptions claires et concises. Cela aidera les utilisateurs à comprendre rapidement le contenu de la page et à décider s'ils doivent ou non la consulter.
- Recherche interne : si votre site comporte beaucoup de contenu, vous devriez envisager d'ajouter une fonction de recherche interne. Cela permettra aux utilisateurs de trouver rapidement les informations qu'ils recherchent sans avoir à naviguer dans le site.
- Tests utilisateurs : enfin, il est important de tester régulièrement votre architecture d'information en faisant tester votre site par des utilisateurs réels. Cela vous aidera à identifier les problèmes et les lacunes de votre architecture, afin que vous puissiez les corriger et améliorer l'expérience utilisateur.
L'architecture de l'information d'un site web est également importante pour les moteurs de recherche, car elle aide les robots d'exploration à comprendre la structure du site et la hiérarchie de son contenu. Une architecture d'information propre et organisée peut faciliter l'indexation du contenu et améliorer le classement dans les résultats de recherche.
Une structure de site logique et claire, avec une navigation cohérente et facile à suivre, peut également aider les moteurs de recherche à comprendre les relations entre les différentes pages et sections du site. Cela peut aider à renforcer les signaux de pertinence pour les mots clés cibles et à améliorer la visibilité du site dans les résultats de recherche pertinents.
En outre, une architecture de site propre et organisée peut aider à éviter les erreurs de navigation courantes qui peuvent empêcher les robots d'exploration de voir l'intégralité du site, telles que des liens cassés ou des pages orphelines.
Utilisez-vous des plans de site (Sitemaps)?
Un sitemap est exactement ce à quoi il ressemble: une liste d'URL de votre site que les robots d'exploration peuvent utiliser pour découvrir et indexer votre contenu. L'un des moyens les plus simples de vous assurer que Google trouve vos pages les plus prioritaires est de créer un fichier qui répond aux normes de Google et de le soumettre via Google Search Console. Bien que la soumission d'un sitemap ne remplace pas la nécessité d'une bonne navigation sur le site, elle peut certainement aider les robots d'exploration à suivre un chemin vers toutes vos pages importantes.
Assurez-vous que vous n'avez inclus que les URL que vous souhaitez indexer par les moteurs de recherche, et assurez-vous de donner aux robots des directions cohérentes. Par exemple, n'incluez pas d'URL dans votre sitemap si vous avez bloqué cette URL via robots.txt ou incluez des URL dans votre sitemap qui sont des doublons plutôt que la version canonique préférée (nous fournirons plus d'informations sur la canonisation dans le chapitre 5 (référencement technique).
Les robots d'exploration reçoivent-ils des erreurs lorsqu'ils tentent d'accéder à vos URL?
Oui, les robots d'exploration peuvent recevoir des erreurs lorsqu'ils tentent d'accéder à des URL. Les erreurs les plus courantes sont les erreurs 404 (Page non trouvée) et les erreurs 500 (Erreur du serveur).
L'erreur 404 se produit lorsque le robot d'exploration essaie d'accéder à une URL qui n'existe plus ou qui a été déplacée. Ce genre d'erreur peut se produire pour diverses raisons, telles que la suppression de pages, la modification de l'URL ou l'erreur de saisie.
L'erreur 500 se produit lorsque le serveur ne peut traiter la requête envoyée par le robot d'exploration. Ce genre d'erreur peut se produire en raison d'un problème de serveur, d'un problème de configuration du site ou d'une erreur de code.
Il est important de surveiller ces erreurs et de les résoudre dès que possible pour minimiser les effets négatifs sur le référencement naturel. Les erreurs peuvent faire perdre du temps et des ressources aux robots d'exploration et peuvent également affecter la qualité de l'expérience utilisateur en empêchant les utilisateurs de trouver les informations qu'ils recherchent sur votre site.
Lors de l'exploration des URL sur votre site, un robot peut rencontrer des erreurs. Vous pouvez accéder au rapport "Erreurs d'exploration" de la Google Search Console pour détecter les URL sur lesquelles cela peut se produire. Ce rapport vous montrera les erreurs du serveur, les erreurs sur les pages non trouvées et encore plus.
Codes 4xx: lorsque les robots des moteurs de recherche ne peuvent pas accéder à votre contenu en raison d'une erreur client
Les erreurs 4xx de Google sont des codes d'erreur HTTP qui indiquent que le client (dans ce cas, le robot d'exploration de Google) a rencontré un problème lors de l'accès à une URL. Les erreurs 4xx les plus courantes sont :
- 401 Unauthorized: Indique que l'authentification est requise pour accéder à la ressource.
- 403 Forbidden: Indique que le client n'a pas la permission d'accéder à la ressource.
- 404 Not Found: Indique que la ressource n'a pas été trouvée sur le serveur.
- 410 Gone: Indique que la ressource a été supprimée et n'est plus disponible.
- 451 Unavailable for Legal Reasons: Indique que la ressource est inaccessible en raison de restrictions légales.
Ces erreurs peuvent se produire pour plusieurs raisons, telles que des problèmes de configuration du serveur, des restrictions d'accès à certaines ressources (pages), des ressources qui ont été supprimées ou déplacées sans redirection, etc. Il est important de résoudre les erreurs 4xx pour permettre à Googlebot de mieux comprendre et indexer votre site Web.
Codes 5xx: lorsque les robots des moteurs de recherche ne peuvent pas accéder à votre contenu en raison d'une erreur de serveur
Les codes d'erreur 5xx indiquent que le serveur Web rencontre une erreur lors de la tentative de traitement d'une demande effectuée par les robots d'exploration des moteurs de recherche. Les codes d'erreur 5xx les plus courants sont :
- 500 Internal Server Error: cette erreur se produit lorsque le serveur ne peut traiter une demande en raison d'une erreur interne.
- 502 Bad Gateway: cette erreur se produit lorsqu'un serveur intermédiaire rencontre une erreur lorsqu'il essaie de transmettre une demande à un autre serveur.
- 503 Service Unavailable: cette erreur se produit lorsque le serveur n'est pas disponible pour traiter les demandes en raison de la maintenance ou de la surcharge de trafic.
Ces erreurs peuvent survenir pour diverses raisons, telles que des problèmes de configuration du serveur, des erreurs dans le code du site Web, des problèmes de connexion réseau, etc. Il est important de résoudre rapidement ces erreurs pour maintenir la qualité du site Web et garantir une bonne expérience utilisateur pour les visiteurs et les robots d'exploration.
Les erreurs 5xx sont des erreurs de serveur, ce qui signifie que le serveur sur lequel se trouve la page Web n'a pas répondu à la demande du chercheur ou du moteur de recherche d'accéder à la page. Dans le rapport "Erreur d'exploration" de Google Search Console, un onglet est dédié à ces erreurs. Cela se produit généralement parce que la demande d'URL a expiré, Googlebot a donc abandonné la demande. Consultez la documentation de Google pour en savoir plus sur la résolution des problèmes de connectivité du serveur.
Heureusement, il existe un moyen de dire aux chercheurs et aux moteurs de recherche que votre page a été déplacée, la redirection 301 (permanente).
Créez des pages 404 personnalisées!
Personnalisez votre page 404 en ajoutant des liens vers des pages importantes de votre site, une fonction de recherche de site et même des informations de contact. Cela devrait rendre moins probable que les visiteurs rebondissent sur votre site lorsqu'ils atteignent une erreur 404.
Supposons que vous déplacez une page de Yoomweb.com/SEO/ vers Yoomweb.com/SEO/ technique. Les moteurs de recherche et les utilisateurs ont besoin d'un pont pour passer de l'ancienne URL à la nouvelle. Vous pouvez utiliser redirection 301 pour informer les moteurs de recherche.
Il ne faut cependant pas trop casser la tête avec des pages que vous avez supprimées et que ne voulez plus qu’elles s’affichent sur les moteurs de recherche. Cela est très normal. Exemple : vous ne vendez plus un produit que vous avez dans votre boutique.
Le code d'état 301 lui-même signifie que la page a été définitivement déplacée vers un nouvel emplacement, évitez donc de rediriger les URL vers des pages non pertinentes.
Si une page est classée pour une requête et que vous la définissez sur une URL avec un contenu différent, elle peut tomber en position de classement, car le contenu qui la rendait pertinente pour cette requête particulière n'est plus là. Les 301 sont puissants, mais il faut les utiliser de manière responsable!
Vous avez également la possibilité de rediriger une page 302, mais cela devrait être réservé aux déplacements temporaires et dans les cas où le passage de l'équité du lien n'est pas aussi important. Les 302 sont un peu comme un détour par la route. Vous siphonnez temporairement du trafic sur un certain itinéraire, mais ce ne sera pas comme ça pour toujours.
Attention aux chaînes de redirection!
Il peut être difficile pour Googlebot d'accéder à votre page si elle doit passer par plusieurs redirections. Google appelle ça « chaînes de redirection » et il recommande de les limiter autant que possible. Si vous redirigez yoomweb.com/page1 vers yoomweb.com/page2, puis décidez plus tard de le rediriger vers yoomweb.com/page3, il est préférable d'éliminer l'intermédiaire et de simplement rediriger yoomweb.com/page1 vers yoomweb.com/page3.
Une fois que vous avez vérifié que votre site est optimisé pour l'exploration, la prochaine étape consiste à vous assurer qu'il peut être indexé.
Indexation: comment les moteurs de recherche interprètent-ils et stockent-ils vos pages?
Les moteurs de recherche utilisent des robots ou des araignées pour parcourir et indexer les pages web. Lorsqu'un moteur de recherche trouve une page, il analyse le contenu de cette page et de ses liens pour en comprendre le sujet et l'importance relative.
Les moteurs de recherche utilisent différents algorithmes pour comprendre et classer les pages web, mais les éléments suivants sont souvent pris en compte :
- Le contenu du texte : Les moteurs de recherche analysent le contenu du texte pour comprendre le sujet de la page et déterminer si elle est pertinente pour une requête de recherche particulière.
- Les balises de titre et de méta-description : Les balises de titre et de méta-description peuvent donner aux moteurs de recherche une idée de ce à quoi s'attendre sur une page et comment elle peut répondre aux besoins des utilisateurs.
- Les liens entrants et sortants : Les moteurs de recherche prennent en compte les liens entrants et sortant d'une page pour comprendre l'importance relative de la page et comment elle s'intègre à l'ensemble du site web.
- Les images et les vidéos : Les moteurs de recherche utilisent les informations de métadonnées telles que les balises ALT pour comprendre le contenu des images et des vidéos sur une page.
Une fois que les moteurs de recherche ont analysé une page, ils stockent le contenu dans leur base de données pour une recherche rapide et efficace lorsque des utilisateurs effectuent des requêtes de recherche. Les moteurs de recherche peuvent mettre à jour régulièrement leur index pour refléter les changements sur le site web.
En conclusion, les moteurs de recherche interprètent et stockent les pages web en analysant le contenu et les liens pour comprendre le sujet et l'importance relative, et en utilisant ces informations pour classer les pages pour les requêtes de recherche.
Puis-je voir comment un robot d'exploration Googlebot voit mes pages?
Oui, la version mise en cache de votre page reflétera un instantané de la dernière fois que Googlebot l'a explorée.
Google explore et met en cache les pages Web à différentes fréquences. Des sites plus connus et bien établis qui publient fréquemment seront explorés plus fréquemment que les sites Web moins connus.
Vous pouvez voir à quoi ressemble votre version en cache d'une page en cliquant sur la flèche déroulante à côté de l'URL dans le SERP et en choisissant "En cache":

Vous pouvez également utiliser Google Search Consol (GSC) pour afficher comment Google voit votre page dans la section Inspection d’une URL.

Les pages sont-elles jamais supprimées de l'index?
Oui, les pages peuvent être supprimées de l'index! Certaines des principales raisons pour lesquelles une URL peut être supprimée sont les suivantes:
L'URL renvoie une erreur "introuvable" (4XX) ou une erreur de serveur (5XX). Cela peut être accidentel (la page a été déplacée et une redirection 301 n'a pas été configurée) ou intentionnelle (la page a été supprimée et 404 modifiée afin de le retirer de l'index)
- L'URL avait une balise méta NoIndex ajoutée : Cette balise peut être ajoutée par les propriétaires de sites pour demander aux moteurs de recherche de ne pas indexer cette page.
- L'URL a été pénalisée manuellement pour avoir enfreint les consignes aux webmasters d’un moteur de recherche et, par conséquent, a été supprimée de l'index.
- L'exploration de l'URL a été bloquée avec l'ajout d'un mot de passe requis avant que les visiteurs puissent accéder à la page.
Si vous pensez qu'une page de votre site Web qui figurait auparavant dans l'index de Google ne s'affiche plus, vous pouvez utiliser Google Search Consol (L’outil Google pour les webmasters) pour connaître l'état de la page en question en utilisant la fonctionnalité d’inspection en direct.
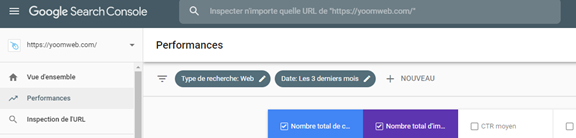
Outil de l’inspection de l’url de Google Search Consol
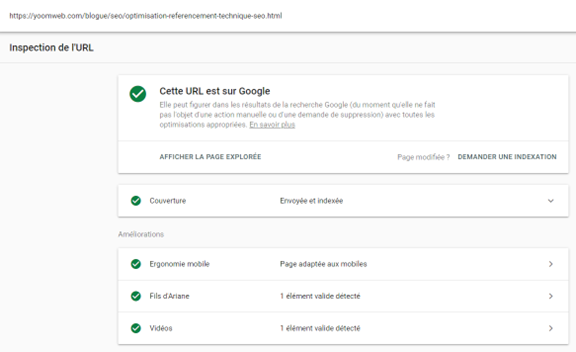
Vous pouvez également demander l’indexation ou la re-indexation d’une URL en utilisant la fonctionnalité de Google Search Consol « Demander une indexation ».
L’outil vous offre également l’option de « rendu » qui vous permet de voir s'il y a des problèmes avec la façon dont Google voit et interprète votre page.
Dans la section « Couverture » de GSC, vous aurez un aperçu de toutes vos pages réussies ou exclues ainsi que la raison de leur exclusion.
Note : Il est normal que vous alliez trouver des pages exclues, l’objectifs est de ne pas faire le tout pour indexer les pages exclues, mais plutôt d’analyser s’il y a des problématiques sur votre site et s’il y a des pages pertinentes exclues de l’index de Google.
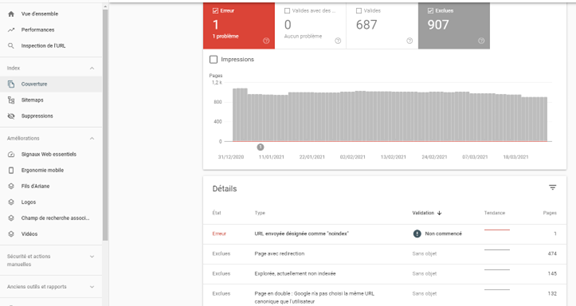
Section « Couverture » de Google Search Consol »
Dites aux moteurs de recherche comment indexer votre site
Méta-directives robots
Les méta-directives robots sont des balises HTML qui sont ajoutées à l'en-tête d'une page Web pour indiquer aux moteurs de recherche comment ils doivent indexer et suivre cette page. Les deux méta-directives les plus courantes sont "noindex" et "nofollow".
"noindex" est utilisé pour indiquer aux moteurs de recherche de ne pas indexer la page. Cela peut être utile si vous ne voulez pas que la page apparaisse dans les résultats de recherche, ou si la page est une version dupliquée d'une autre page sur votre site.
"nofollow" est utilisé pour indiquer aux moteurs de recherche de ne pas suivre les liens présents sur la page. Cela peut être utile si vous ne voulez pas que les moteurs de recherche suivent des liens vers des pages qui n'ont pas besoin d'être indexées, comme des pages de confirmation de commande ou des pages d'inscription.
Il existe également d'autres méta-directives robots moins courantes, comme "noarchive", qui empêche les moteurs de recherche de stocker une copie en cache de la page, ou "nosnippet", qui empêche les extraits de la page d'apparaître dans les résultats de recherche.
Mais ne vous inquiétez pas. Ça semble assez technique, mais la majorité de CMS comme Joomla! ou Wordpress vous permettent de les gérer facilement.
Balise Meta Robots
La balise META robots peut être utilisée dans le <head> du code HTML de votre page Web. Il peut exclure tout ou certains moteurs de recherche. Voici les méta-directives les plus courantes, ainsi que les situations dans lesquelles vous pouvez les appliquer.
Index / noindex indique aux moteurs si la page doit être explorée et conservée dans l'index d'un moteur de recherche pour être récupérée.
Si vous choisissez d'utiliser la balise "noindex", vous communiquez aux robots d'exploration que vous souhaitez que la page soit exclue des résultats de recherche.
Follow / nofollow indique aux moteurs de recherche si les liens sur la page doivent être suivis ou non suivis.
«follow» se traduit par des robots qui suivent les liens sur votre page et transmettent l'équité des liens à ces URL.
Si vous choisissez d'employer le «nofollow», les moteurs de recherche ne suivront pas le lien et ne transmettront aucune. Par défaut, toutes les pages sont supposées avoir l'attribut "Follow".
Les directives méta affectent l'indexation, pas l'analyse
Googlebot doit explorer votre page pour voir ses méta-directives, donc si vous essayez d'empêcher les robots d'exploration d'accéder à certaines pages, les méta-directives ne sont pas le moyen de le faire. Les balises de robots doivent être explorées pour être respectées.
X-Robots-Tag
La balise x-robots est utilisée dans l'en-tête HTTP de votre URL, offrant plus de flexibilité et de fonctionnalité que les balises META si vous souhaitez bloquer les moteurs de recherche à grande échelle car vous pouvez utiliser des expressions régulières, bloquer des fichiers non-HTML et appliquer des balises noindex à l'échelle du site.
Les dérivés utilisés dans une balise META de robots peuvent également être utilisés dans une balise X-Robots. Ce sont des fonctionnalités que nous utilisons rarement d’habite, mais c’est bon de le savoir.
Pour plus d'informations sur les balises Meta Robot, explorez les spécifications des balises Meta de Google.
Dans la majorité des cas, vous n’êtes pas obligé de programmer cela manuellement, la majorité des CMS vous permettent de le faire en ajustant des paramètres dans leur panneau de configuration.
Comprendre les différentes façons dont vous pouvez influencer l'exploration et l'indexation de votre site vous aidera à éviter les pièges courants qui peuvent empêcher la découverte de vos pages importantes.
Classement: comment les moteurs de recherche classent-ils les URL?
Les moteurs de recherche utilisent des algorithmes complexes pour déterminer la pertinence des pages Web pour une requête de recherche particulière. Cela implique l'analyse de nombreux facteurs différents, tels que la pertinence du contenu, la qualité et l'autorité du site, la qualité et la pertinence des liens entrants, l'historique de la page et bien plus encore.
Lorsqu'un utilisateur tape une requête dans la barre de recherche, l'algorithme de classement de Google analyse toutes les pages Web qui peuvent correspondre à la requête et classe les pages les plus pertinentes en premier. Les algorithmes prennent en compte de nombreux facteurs différents pour déterminer la pertinence, y compris la présence de mots clés pertinents dans le titre et le corps du contenu, la pertinence des médias, tels que les images et les vidéos, la qualité et la pertinence des liens entrants et la qualité générale du site.
Il est important de noter que les algorithmes de classement des moteurs de recherche sont constamment mis à jour et modifiés, il est donc important de rester informé des dernières mises à jour pour maximiser la pertinence et le classement des résultats de recherche pour un site donné.
Pourquoi l'algorithme change-t-il si souvent? L'algorithme de Google change souvent afin de fournir aux utilisateurs les meilleurs résultats de recherche possibles. Les algorithmes doivent évoluer pour tenir compte des nouvelles techniques de spam, des nouveaux types de contenu en ligne et des attentes des utilisateurs en constante évolution. Google effectue régulièrement des mises à jour de son algorithme pour s'assurer que les résultats de recherche restent pertinents et de qualité. Les mises à jour de l'algorithme sont un moyen pour Google de lutter contre les tactiques douteuses d'optimisation pour les moteurs de recherche (SEO) et de maintenir un haut niveau d'éthique pour les résultats de recherche.
Que veulent les moteurs de recherche?
Les moteurs de recherche veulent toujours fournir des réponses utiles aux questions des utilisateurs. Cependant, au fil du temps, leur compréhension de la langue a évolué pour devenir plus avancée. Ils peuvent désormais comprendre les nuances et deviner l'intention de la recherche de l'utilisateur.
Au début, les algorithmes de recherche étaient rudimentaires et il était plus facile de jouer avec le système en utilisant des tactiques comme le bourrage de mots clés. Cependant, cela a entraîné des expériences utilisateur médiocres pour les internautes et n'a jamais été ce que les moteurs de recherche voulaient.
Les algorithmes continuent d'évoluer pour favoriser des résultats de qualité, pertinents et utiles pour les utilisateurs. Les tactiques qui vont à l'encontre des directives de qualité ont moins d'impact et les moteurs de recherche mettent en œuvre des mesures pour les détecter et les éliminer.
Le rôle des liens (Backlinks) dans le référencement
Les liens entrants ou "backlinks" jouent un rôle important dans le référencement (SEO). Les moteurs de recherche considèrent les backlinks comme des votes de confiance pour le site lié. Si de nombreux sites de qualité renvoient à une page particulière, les moteurs de recherche peuvent en déduire que cette page est importante et digne d'être classée plus haut dans les résultats de recherche.
Cependant, la qualité des liens est tout aussi importante que leur quantité. Les moteurs de recherche accordent plus de poids aux liens provenant de sites qui sont autoritaires et fiables dans leur domaine. De plus, les liens contextuels, c'est-à-dire les liens qui sont intégrés à un contenu de qualité et qui renvoient à une page pertinente, sont généralement plus précieux que les liens dans les annuaires ou les commentaires de blog peu pertinents.
Il est important de noter que les tactiques de construction de liens peu éthiques, telles que les échanges de liens ou les liens achetés, peuvent entraîner des pénalités de référencement de la part des moteurs de recherche. Il est préférable de se concentrer sur la production de contenu de qualité qui attire naturellement des liens entrants pertinents et respectables.
Le rôle que joue le contenu dans le référencement
Les liens ne serviraient à rien s'ils ne dirigeaient pas les chercheurs vers quelque chose d’intéressant. On parle ici du contenu. Le contenu est plus que de simples mots; c'est tout ce qui est destiné à être consommé par les chercheurs, contenu vidéo, contenu image et bien sûr du texte. Si les moteurs de recherche sont des répondeurs, le contenu est le moyen par lequel les moteurs fournissent ces réponses.
Chaque fois que quelqu'un effectue une recherche, il y a des milliers voire des millions de résultats possibles, alors comment les moteurs de recherche décident-ils des pages que le chercheur va trouver utiles? Une grande partie de la détermination du classement de votre page pour une requête donnée est de savoir dans quelle mesure le contenu de votre page correspond à l'intention de la requête. En d'autres termes, cette page correspond-elle aux mots qui ont été recherchés et aide-t-elle à accomplir la tâche que le chercheur tentait d'accomplir?
En raison de cette concentration sur la satisfaction des utilisateurs et l'accomplissement des tâches, il n'y a pas de référence stricte sur la durée de votre contenu, le nombre de fois qu'il doit contenir un mot-clé ou ce que vous mettez dans vos balises d'en-tête. Tous ceux-ci peuvent jouer un rôle dans la performance d'une page dans la recherche, mais l'accent doit être mis sur les utilisateurs qui liront le contenu.
Aujourd'hui, avec des centaines voire des milliers de signaux de classement, les trois premiers sont restés assez cohérents: liens vers votre site Web (qui servent de signaux de crédibilité), contenu sur la page (contenu de qualité qui répond à l'intention d'un chercheur) et le RankBrain.
Qu'est-ce que RankBrain?
RankBrain est un algorithme de machine learning développé par Google pour améliorer les résultats de recherche. Il fait partie de l'algorithme général de recherche de Google et aide à comprendre le sens des requêtes de recherche complexes et à fournir des résultats plus pertinents.
RankBrain utilise l'apprentissage automatique pour comprendre le langage naturel et les concepts sous-jacents dans les requêtes de recherche, plutôt que de simplement correspondre aux mots clés dans les pages web. Cela permet à RankBrain de comprendre les requêtes de recherche vagues ou imprécises et de les relier à des résultats pertinents.
RankBrain peut également apprendre de ses erreurs et améliorer continuellement ses résultats en fonction des commentaires des utilisateurs sur les résultats de recherche. Cela signifie que RankBrain peut s'adapter et s'améliorer au fil du temps pour fournir des résultats de recherche toujours plus pertinents pour les utilisateurs.
En résumé, RankBrain est un algorithme de machine learning de Google qui aide à comprendre les requêtes de recherche complexes et à fournir des résultats de recherche pertinents en utilisant l'apprentissage automatique pour comprendre le langage naturel et les concepts sous-jacents.
Qu'est-ce que cela signifie pour les référenceurs?
RankBrain est un algorithme de traitement du langage naturel utilisé par Google pour comprendre les requêtes de recherche des utilisateurs. Il est conçu pour traiter les requêtes complexes et les interpréter de manière plus précise pour fournir des résultats de recherche pertinents.
En ce qui concerne le SEO (Search Engine Optimization), RankBrain peut avoir un impact sur le classement des pages dans les résultats de recherche. En utilisant des techniques d'apprentissage automatique, RankBrain peut améliorer la compréhension de la signification sous-jacente des requêtes de recherche, ce qui peut conduire à des résultats de recherche plus pertinents et plus adaptés aux besoins des utilisateurs.
Pour maximiser leur classement dans les résultats de recherche, les sites web doivent s'assurer de produire du contenu de qualité qui répond aux besoins et aux attentes des utilisateurs. Les stratégies SEO telles que la production de contenu de qualité, la construction de liens entrants de qualité et l'optimisation des balises de titre et de méta-description peuvent continuer à aider les sites web à mieux se classer dans les résultats de recherche, même avec l'utilisation de RankBrain.
En conclusion, RankBrain est un algorithme de traitement du langage naturel développé par Google pour comprendre les requêtes de recherche des utilisateurs et fournir des résultats de recherche plus pertinents. Son rôle en SEO est d'améliorer la compréhension des requêtes de recherche et de fournir des résultats de recherche plus pertinents, ce qui peut avoir un impact sur le classement des pages dans les résultats de recherche.
Mesures d'engagement: corrélation, causalité ou les deux?
Avec les classements Google, les mesures d'engagement sont très probablement en corrélation partielle et une causalité partielle.
Lorsque nous parlons de mesures d'engagement, nous entendons des données qui représentent la façon dont les chercheurs interagissent avec votre site à partir des résultats de recherche. Cela inclut des choses comme:
- Le temps passé sur le site
- Le nombre de pages visitées
- Le taux de rebond (le pourcentage de personnes qui quittent votre site après avoir visité une seule page)
Ces mesures d'engagement sont en corrélation avec les classements Google car ils montrent comment les utilisateurs réagissent à votre site lorsqu'ils le trouvent dans les résultats de recherche. Si les gens passent plus de temps sur votre site et visitent plusieurs pages, cela peut suggérer que votre contenu est pertinent et utile pour leur recherche. Cela peut alors être considéré comme un signal positif pour Google, ce qui peut contribuer à améliorer votre classement.
En même temps, il est important de se rappeler que les mesures d'engagement ne sont qu'une partie du puzzle et qu'il existe de nombreux autres facteurs qui peuvent affecter vos classements, tels que la qualité du contenu, la pertinence des mots clés, la structure du site et les liens entrants. Par conséquent, la causalité entre les mesures d'engagement et les classements Google est partielle. Il peut y avoir d'autres facteurs qui causent à la fois les mesures d'engagement et les classements élevés.
Ce que Google a dit
Google a confirmé l'utilisation de données de clic pour ajuster les résultats de la recherche pour des requêtes particulières. Bien que Google ne les appelle pas "signal de classement direct", les mesures d'engagement sont utilisées pour améliorer la qualité de la recherche et le classement des URL individuelles en est un sous-produit. Des tests et études ont montré que le comportement des utilisateurs peut avoir un impact sur le classement des pages dans les résultats de recherche. Les SEO devraient donc se concentrer sur l'optimisation de l'engagement pour aider à évaluer la qualité d'une page Web. Les mesures d'engagement agissent comme un indicateur de l'intérêt des utilisateurs pour les pages, ajustant le classement si nécessaire pour s'adapter aux préférences des chercheurs.
L'évolution des résultats de recherche
À l'époque où les moteurs de recherche manquaient beaucoup de sophistication qu'ils ont aujourd'hui, le terme «10 liens bleus » a été inventé pour décrire la structure basique du SERP. Chaque fois qu'une recherche était effectuée, Google renvoyait une page avec 10 résultats organiques, tous dans le même format.
Avec du temps, Google a commencé à ajouter de nouveaux formats de résultats sur ses pages de résultats de recherche, appelées fonctionnalités SERP (Google SERP Features). Certaines de ces fonctionnalités incluent:
- Annonces payantes
- Extraits enrichis
- D'autres personnes ont également demandé
- Pack local (carte)
- Graph de connaissances
- Liens annexes
- Images
- Recettes de cuisine
- Vidéos
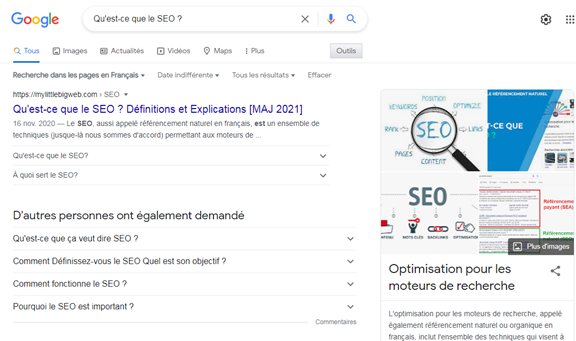
Google en ajoute de nouveaux tout le temps. Il a même expérimenté des « SERP à résultat nul », un phénomène où un seul résultat du graphe de connaissances était affiché sur le SERP sans aucun résultat en dessous, à l'exception d'une option pour « afficher plus de résultats ».
D’après MOZ, l'ajout de ces fonctionnalités a provoqué une certaine panique initiale pour deux raisons principales. D'une part, bon nombre de ces fonctionnalités ont entraîné une baisse des résultats organiques sur le SERP. Un autre inconvénient pour les propriétaires des sites est que moins de chercheurs cliquent sur les résultats organiques car plus de requêtes sont répondues sur le SERP lui-même.
Alors, pourquoi Google ferait-il cela? Tout revient à l'expérience de recherche. Le comportement de l'utilisateur indique que certaines requêtes sont mieux satisfaites par différents formats de contenu. Chaque fonctionnalité SERP (type d’affiche) correspond à un type d'intention de recherche. Exemple : une intention locale correspond à un résultat sous forme de pack de cartes.
Nous parlerons davantage de l'intention de la recherche dans le chapitre 3 (recherche de mots clés), mais pour l'instant, il est important de savoir que les réponses peuvent être fournies aux chercheurs dans un large éventail de formats, et la structure de votre contenu peut avoir un impact sur le format dans lequel il apparaît dans la recherche.
Recherche locale
Un moteur de recherche comme Google possède son propre index propriétaire des fiches d'entreprise locales, à partir duquel il crée des résultats de recherche locaux.
Si vous effectuez un travail de référencement local pour une entreprise qui a un emplacement physique que les clients peuvent visiter (ex: magasin de vêtements) ou pour une entreprise qui voyage pour rendre visite à leurs clients (ex: électricien), assurez-vous que vous revendiquez, vérifiez et optimisez votre fiche Google Profil d’entreprise.
En ce qui concerne les résultats de recherche locales, Google utilise trois facteurs principaux pour déterminer le classement:
1. Pertinence
2. Distance
3. Importance
Pertinence
La pertinence est la mesure dans laquelle une entreprise locale correspond à ce que le chercheur recherche. Pour vous assurer que l'entreprise fait tout ce qui est en son pouvoir pour être pertinente pour les chercheurs, assurez-vous que les informations sur l'entreprise sont remplies de manière approfondie et précise.
Distance
Google utilise votre géolocalisation pour mieux vous servir les résultats locaux. Les résultats de la recherche locale sont extrêmement sensibles à la proximité, qui fait référence à l'emplacement du chercheur et / ou à l'emplacement spécifié dans la requête (si le chercheur en a inclus un).
Les résultats de recherche organiques sont sensibles à l'emplacement d'un chercheur, bien que rarement aussi prononcés que dans les résultats des packs locaux.
Importance
Google cherche à récompenser les entreprises bien connues dans le monde réel. En plus de la visibilité hors ligne d'une entreprise, Google se penche également sur certains facteurs en ligne pour déterminer le classement local, tels que:
Commentaires
Le nombre d'avis Google reçus par une entreprise locale et le sentiment de ces avis ont un impact notable sur leur capacité à se classer dans les résultats locaux.
Citations
Une « citation commerciale » ou « une fiche d’entreprise » dans les autres annuaires locaux (nom, adresse, numéro de téléphone) comme Yelp, Acxiom, YP, Infogroup, Localeze, etc. peuvent aider votre fiche Google à bien se classer.
Les classements locaux sont influencés par le nombre et la cohérence des citations d'entreprises locales. Google tire des données d'une grande variété de sources pour constituer en permanence son index commercial local. Lorsque Google trouve plusieurs références cohérentes au nom, à l'emplacement et au numéro de téléphone d'une entreprise, cela renforce la « confiance » de Google dans la validité de ces données. Cela permet alors à Google de montrer l'entreprise avec un degré de confiance plus élevé. Google utilise également des informations provenant d'autres sources sur le Web, telles que des liens et des articles.
Classement naturel
Les meilleures pratiques de référencement s'appliquent également au référencement local, car Google prend également en compte la position d'un site Web dans les résultats de recherche organiques lors de la détermination de son classement local.
Dans le chapitre suivant, vous découvrirez les meilleures pratiques SEO sur la page (OnPage) qui aideront Google et les utilisateurs à mieux comprendre votre contenu.
Sans aucun doute plus que jamais auparavant, les résultats locaux sont influencés par les données du monde réel. Cette interactivité est la façon dont les chercheurs interagissent avec les entreprises locales et y répondent, plutôt que des informations purement statiques comme les liens et les citations.
Étant donné que Google souhaite fournir aux utilisateurs les meilleures entreprises locales et les plus pertinentes, il est parfaitement logique qu'elles utilisent des mesures d'engagement en temps réel pour déterminer la qualité et la pertinence.
Vous n'avez pas besoin de connaître les tenants et aboutissants de l'algorithme de Google (cela reste un mystère!), Mais vous devriez maintenant avoir une grande connaissance de base de la façon dont le moteur de recherche trouve, interprète, stocke et classe le contenu de votre site. Armés de ces connaissances, apprenons maintenant à choisir les mots clés que votre contenu ciblera dans le chapitre 3 : recherche des mots clés.
- Qu'est-ce que le Web Scraping et à quoi sert-il ?
- Comment les moteurs de recherche affichent les résultats de la recherche
- 3 raisons essentielles pour concentrer vos efforts de marketing sur les moteurs de recherche
- 5 façons pour maintenir le classement de votre site sur les moteurs de recherche ( SEO)